NotORM
Školení, která pořádám 
Většina webových aplikací potřebuje pracovat s propojenými daty uloženými v databázi. Psát SQL dotazy spojující třeba šest tabulek v databázi může být zpočátku docela zábavné, pak se z toho ale stane nudná rutina. Navíc spojení tabulek nemusí být vždy nejefektivnější, protože se znovu přenáší už jednou přenesená data. Takže někdy je výhodnější položit šest jednoduchých dotazů a propojit až jejich výsledky, což už je úplná nuda.
Článek vyšel na serveru Zdroják.
Elegance
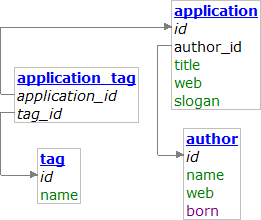
Pro získání dat pomocí PHP proto vznikla knihovna, která propojená data z databáze dokáže elegantně a zároveň efektivně získat. Jmenuje se NotORM a připodobnil bych ji k PHP extenzi SimpleXML, která podobným způsobem pracuje s XML dokumenty. Základní API je jednoduché:
<?php // připojení k databázi include "NotORM.php"; $pdo = new PDO("mysql:dbname=software"); $software = new NotORM($pdo); // získání prvních deseti aplikací foreach ($software->application()->order("title")->limit(10) as $application) { // vypsání jejich titulku echo $application["title"]; // získání jména autora z propojené tabulky echo " (" . $application->author["name"] . ")\n"; // vypsání všech nálepek z propojené tabulky M:N foreach ($application->application_tag() as $application_tag) { echo "- " . $application_tag->tag["name"] . "\n"; } } ?>
Efektivita
Jak už bylo řečeno, tak knihovna je nejen elegantní, ale zároveň i efektivní. Klade tedy jen minimální počet jednoduchých dotazů a z databáze přenáší jen ta data, která jsou potřeba. Dosahuje se toho dvěma způsoby:
- Získání souvisejících záznamů se provádí najednou pro všechny řádky výsledku jedním dotazem.
- Přenášejí se jen ty sloupce, které se nakonec skutečně použijí (při povolení této vlastnosti).
Díky těmto vlastnostem se pro zpracování příkladu položí jen čtyři jednoduché dotazy:
SELECT id, title, author_id FROM application ORDER BY title LIMIT 10;
SELECT id, name FROM author WHERE (id IN ('11', '12'));
SELECT application_id, tag_id FROM application_tag WHERE (application_id IN ('1', '4', '2', '3'));
SELECT id, name FROM tag WHERE (id IN ('21', '22', '23'));
Všimněte si, že z tabulek se přenáší jen ty sloupce, které se nakonec použijí, aniž by se jejich seznam musel kdekoliv specifikovat. To je zařízeno tak, že knihovna napoprvé získá všechny sloupce, pak si ale zapamatuje, které sloupce skutečně použila a příště už si vyžádá jen ty použité. Když se skript změní a chceme vypsat nějaké sloupce navíc, tak se automaticky zase získají všechny a seznam se rozšíří. Pro zajištění tohoto chování si knihovna potřebuje ukládat data, což lze nastavit třetím parametrem konstruktoru NotORM – jsou připravena úložiště do session proměnných, souborů, databáze a sdílené paměti, další si můžete snadno doplnit.
Kešování výsledků dotazů knihovna nepoužívá, protože takováto keš zastarává a navíc zabírá paměť, kterou lze využít k něčemu užitečnějšímu. Lepší je data získávat efektivně rovnou od databáze, pro což dává knihovna výborné podmínky.
Struktura databáze
NotORM umí pracovat se všemi databázemi, které podporuje PDO, testovaná je s MySQL, SQLite, PostgreSQL a MS SQL. Kromě toho je NotORM k dispozici i pro oblíbenou knihovnu Dibi.
Co se pojmenování sloupců týče, tak se používá nejrozšířenější konvence – primární klíč je id, cizí klíč table_id, kde table je název odkazované tabulky. Předáním druhého parametru konstruktoru NotORM si ale můžeme nastavit i vlastní konvenci. K dispozici je i třída načítající informace o primárních a cizích klíčích přímo z meta-informací databáze (tabulky InnoDB v MySQL >= 5), ta má ale určitou režii, takže je lepší dodržovat nějakou konvenci.
Omezení výsledku hodnotami v jiné tabulce
Řekněme, že bychom chtěli vědět, jakým oblastem se věnuje určitý autor. Neboli zjistit nálepky všech aplikací daného autora. V NotORM to jde velmi snadno:
<?php $applications = $software->application("author_id", 11); foreach ($software->application_tag("application_id", $applications) as $application_tag) { echo $application_tag->tag["name"] . "\n"; } ?>
První řádek zkonstruuje dotaz vracející všechny aplikace daného autora. Tento dotaz se ale databázi samostatně nepoloží, protože jeho výsledkem neprocházíme. Místo toho se použije jako poddotaz na druhém řádku kódu. Celkově se tedy položí tyto dotazy:
SELECT tag_id FROM application_tag WHERE (application_id IN (SELECT id FROM application WHERE (author_id = '11')));
SELECT id, name FROM tag WHERE (id IN ('21', '22', '23'));
Validace a ukládání dat
NotORM se nestará o ukládání a tím pádem ani validaci dat. Ve webových aplikacích je totiž ukládání obvykle mnohem méně časté než načítání a není problém ho zajistit konvenčními způsoby. Pro administrační rozhraní lze použít Adminer Editor, který ukládání vyřeší zadarmo.
Validaci dat je lepší řešit na úrovni databáze pomocí unikátních a cizích klíčů, datových typů, povinných sloupců a dalších kontrol. Jinak totiž hrozí, že se nám do databáze dostanou nekonzistentní data, se kterými aplikace stejně bude muset umět pracovat. Ohlašování chyb uživateli je zase vhodné řešit co nejblíže místu jejich vzniku, výborně se o to starají třeba formuláře Nette.
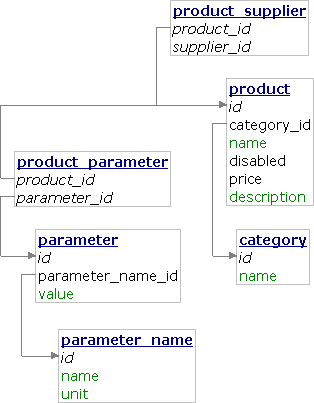
Větší příklad
NotORM se báječně hodí pro malé webíky se třemi propojenými tabulkami stejně jako pro velké projekty s desítkami složitě propojených tabulek. U těchto projektů dává NotORM pocit klidu, že se bez velkého přemýšlení vyhodnocují všechny dotazy efektivně (samozřejmě pokud jsou definované indexy na vyhledávání a třídění). Ukážeme si proto použití u obchodu, který organizuje produkty do kategorií a u každého produktu eviduje jeho možné dodavatele. Kromě toho se k produktům evidují parametry, které se načítají z tabulky všech možných hodnot (ta se používá třeba i pro sestavení vyhledávacího formuláře), která se zase odkazuje do tabulky všech možných názvů parametrů. Na obrázku je pouze relevantní část schématu celé databáze a jsou vynechány nevyužité sloupce.
<?php include "NotORM.php"; $pdo = new PDO("mysql:dbname=shop"); $shop = new NotORM($pdo, null, new NotORM_Cache_Database($pdo)); $category = $shop->category[$_GET["id"]]; if (!$category) { // 404 exit; } echo "<h1>" . htmlspecialchars($category["name"]) . "</h1>\n"; $products = $category->product() ->where("disabled", 0) ->order("price") ->limit(10) ; foreach ($products as $product) { echo "<h3>" . htmlspecialchars($product["name"]) . "</h3>\n"; list($suppliers) = $product->product_supplier()->group("COUNT(*)"); echo "<p>Cena: $product[price] Kč, dodavatelů: $suppliers</p>\n"; $product_parameters = $product->product_parameter(); if (count($product_parameters)) { echo "<table cellspacing='0'>\n"; foreach ($product_parameters as $product_parameter) { $parameter = $product_parameter->parameter; $parameter_name = $parameter->parameter_name; echo "<tr>"; echo "<th>" . htmlspecialchars($parameter_name["name"]) . "</th>"; echo "<td>" . htmlspecialchars("$parameter[value] $parameter_name[unit]") . "</td>"; echo "</tr>\n"; } echo "</table>\n"; } } ?>
Při spuštění se položí následující dotazy:
SELECT id, name FROM category WHERE (id = '25');
SELECT id, category_id, name, price FROM product WHERE (category_id IN ('25')) AND (disabled = '0') ORDER BY price LIMIT 10;
SELECT product_id, COUNT(*) FROM product_supplier WHERE product_id IN ('102920', '102915', '116549', '102902', '108993', '102907', '102900', '102922', '102930', '102909') GROUP BY product_id;
SELECT product_id, parameter_id FROM product_parameter WHERE (product_id IN ('102920', '102915', '116549', '102902', '108993', '102907', '102900', '102922', '102930', '102909'));
SELECT id, parameter_name_id, value FROM parameter WHERE (id IN ('1', '131', '3780', '6109', '2561', '2576', '6110', '3787', '5374', '6111', '6113', '6114', '8783'));
SELECT id, name, unit FROM parameter_name WHERE (id IN ('1', '46', '120', '187'));
Dávat tyto dotazy dohromady ručně nebo konstruovat dotazy spojující více tabulek by se mi opravdu nechtělo. Obslužná logika pro jejich projití by navíc byla prakticky stejná jako u NotORM. Navíc bych nejspíš skoro všude z pohodlnosti použil SELECT *, abych nemusel sloupec dodatečně přidaný do výpisu dopisovat ještě do dotazu.
Závěr
Knihovna NotORM se dá použít pro pohodlné a efektivní procházení propojených záznamů v databázi ať už u malých nebo u velkých projektů. Neřeší validaci ani ukládání dat, které je obvykle lepší řešit na jiné úrovni.
Diskuse
Dr.Diesel:
Hned u vzniku NotORM jsem pro přejmenování order() metody na orderby(), ten order() tam mě osobně bije do očí.11.$products = $category->product()
12. ->where("disabled", 0)
13. ->order("price")
14. ->limit(10)
15.;
P.S. A psaní s diakritikou mi vadí taky, ale máš/máte ji mít :-D
Amot:
Zdravim,jak se da strankovat v pripade, ze parsuju data z pomerne velkeho XML souboru?
Diky za "navedeni",
Amot
cucací potřeby:
Dr.Diesel: nevím, proč by to muselo být zrovna orderby()Jakub: NotORM se mi zalíbilo a musím uznat, že je opravdu elegantní. Z přílišné skromnosti jsi zřejmě neuvedl adresu oné knihovny - http://www.notorm.com/
Why Not ORM? ;-)
mimochodem, může být řádek
<?php $category = $shop->category[$_GET["id"]]; ?>
vystaven SQL injection nebo se případné uvozovky vyescapují?
btw. snahu zjistit nárory druhých pomocí vlastní ankety a zdrojovat to ve článku kvituji kladně, ale něco přes 100 hlasů nyní již uzavřené ankety (na v Čechách ne tak známém serveru) ještě stále nemá takovou vypovídací hodnotu a nevím, jestli bych to propagoval jako (a teď myšleno obecně a globálně) "nejrozšířenější konvence".
a ještě ad nejrozšířenější konvence) obávám se, že ta mixuje singulár u klíče a plurál u názvů tabulky, tj. např. tabulka "categories" ale cizí klíč "category_id", nikoli "categories_id". Mám za to, že plurál se používá pro názvy tabulek častěji, protože takové "SELECT id FROM categories" zní oproti "SELECT id FROM category" lépe. (Možná by to bylo na další anketu :-) )
SimpleXML má s NotORM podobný zápis v kódu, používání metod a přístup k objektům, které ovládá, ale - opravte mě, jestli se mýlím - při vytvoření instance načítá celý zadaný XML soubor do paměti, což je pravý opak toho, co vyzvihuješ na NotORM, není-liž pravda.
 Jakub Vrána
Jakub Vrána  :
:
Odkaz na web je vytvořen z první zmínky o NotORM v článku, jak je to zvykem.
<?php $shop->category[$_GET["id"]] ?> je vůči SQL injection imunní – obecně řečeno se všechna data ošetřují, naopak žádné identifikátory ne.
S tím množným číslem to je asi pravda, ale kód by se kvůli nepravidelnostem zbytečně komplikoval. Nicméně konvence "tables" a "tables_id" bude fungovat taky.
NotORM má se SipleXML podobné API, způsob práce samozřejmě ne.
cucací potřeby:
ad SQL injection) tzn. NotORM všechna data (uvnitř SQL) dává do uvozovek a escapuje?ad množné číslo) právě takové komplikace nemám rád (a to přidávání "-s" nebo "-y" --> "-ies" v angličtině patří ještě mezi ty jednodušší, v češtině by kód na zjišťování množného čísla byl delší než celý projekt). Takže v příštím návrhu nějaké databázové struktury, co se namane, vyzkouším 'singulár'.
Jakub Vrána :
Ošetří se všechno, co se posílá zvlášť. Když napíšeš where("id = $_GET[id]"), tak to samozřejmě ošetřené nebude, ale where("id", $_GET["id"]) ano, stejně jako where("id = ?", array($_GET["id"])).
Ono je celkem jedno, jestli jednotné nebo množné číslo - důležité je, aby se sloupce jmenovaly stejně jako tabulky. Tedy buď products a products_id nebo product a product_id.
Dr.Diesel:
Pokud dobre chapu abstrakci notace NotORM:<?php
include "NotORM.php";
$connection = new PDO("mysql:dbname=software");
$software = new NotORM($connection);
$applications = $software->application()
->select("id, title")
->where("web LIKE ?", "http://%")
->order("title")
->limit(10)
;
?>
SQL:
select id, title
from application
where web like 'http://%'
order by title
limit 10
Proc asi orderby()...
PHX:
Rad bych to zkusil pouzit v jednom projektu, ale mam problem. Napr hned tvuj prvni priklad s App, Autorem a Tagy. Rekneme, ze to bude vypsane v tabulce, ale co kdyz bude pozadavkem uzivatelske razeni dle sloupecku.Jde to nejak jednoduse? Osobne me nenapada cesta. Jedine snad radit v PHP, ale to bych musel nacist vsechny zaznamy.
Jakub Vrána :
Všimni si metody order(). Tou můžeš řadit podle libosti.
PHX:
Jeste jsem nezkousel. Zkusim. Ale pokud to chapu dobre tak tim vlastne poslu do DB dotaz s JOIN jen kuli serazeni (chci radit dle dat z tabulky co budou teprve navazany ve foreach). To uz mozna vyjde levneji rovnou ziskat vsechna data, kdyz uz to DB joinuje kuli razeni, ne? Jakub Vrána :
Pokud chceš WHERE z jedné tabulky a ORDER BY z druhé, tak to efektivní nebude nikdy.
ok3x:
Díval jsem se do mauálu a tohle mě bije do očí:<?php $row2 = $row->$column ?> Get row from referenced table
K čemu se to používá, myslím prakticky? Čekal bych, že to bude něco jako alias zápisu <?php $data = $row[$column] ?> Get data from column, když už je to celé tak pěkně objektové.
Jakub Vrána :
Jde o jeden ze dvou základních obratů. Např. $application->author["name"] získá jméno autora aktuální aplikace. Možná tě mate to $column, ono to je totiž spíš $tableName, i když v závislosti na mapování to může být i něco mezi tím (sloupec se může jmenovat author_id, tabulka authors).
 v6ak:
v6ak:
Nazdar,
trošku jsem se na NotORM díval a přišel jsem na jednu potenciálně nebezpečnou vlastnost. Není to bezpečnostní chyba, je to vlastnost, která umožňuje bezpečnostní chybu (SQL injekci) velmi snadno vytvořit.
Když jsem se díval na http://www.notorm.com/#persistence , nemohl jsem si nevšimnout tohoto:
The $array parameter holds column names in keys and data in values. Values are automatically quoted, SQL literals can be passed as array, for example:
<?php
$array = array(
"title" => "NotORM",
"author_id" => null,
"created" => array("NOW()"),
); ?>
Když si představím třeba "title" => $_POST["title"], je tu slušný prostor pro díru, protože tam mohu dostat i pole. POST bude asi často ošetřen formulářovou knihovnou, ne až tak GET.
Komu nedává smysl to pole na vstupu, toho odkážu na: http://v6ak.profitux.cz/clanky/musi-byt-na-…-string.php
Jakub Vrána :
To je zajímavý postřeh. Mě se tam to pole nelíbí i proto, že jeho smysl není intuitivní. Nahradil bych to objektem, takže pak by se předávalo třeba new NotORM_Literal("NOW()"), souhlasíš?
v6ak:
Jo, naprosto souhlasím. Pole mi přišlo jako hack podobný callbacku array(objekt, metoda).
Jakub Vrána :
Ano, přesně tím jsem se nechal inspirovat.
Jakub Vrána :
Díky za tip, změnil jsem to na onen objekt třídy NotORM_Literal.
Juan:
Jakube, předně díky za NotORM, je to fantastická věc!Mám jeden námět na vylepšení naming conventions. Myslím, že situace, kdy máme dva a více cizích klíčů z jedné tabulky do jediné jiné, může být poměrně častá. Způsob, jak toto řešit, který popisuješ na webu NotORM mi nepřijde úplně elegantní, obvzlášť pokud takových tabulek bude více.
Vede to ke zbytečnému dědění třídy NotORM_Structure_Convention a přidávání podmínek typu:
<?php
if ($name == 'created_by' || $name == 'modified_by') {
return 'user';
}
?>
Co takhle zavést modifikátor, který by odpovídal libovolnému řetězci? Pak by šlo automaticky brát všechny následující varianty jako odkaz do tabulky user:
user_id
user_id_created
user_id_modified
------
Když už jsem u těch námětů na vylepšení, napíšu to sem:
Adminer 2.3.2 krásně automaticky vytváří cizí klíče, pokud je název ve tvaru tabulka_id. To je super věc! Chybí mi tam ale klíč do stejné tabulky (vztah "parent").
Jakub Vrána :
Konvence user_id_created podle mě moc častá není, takže kvůli tomu nechci upravovat společný kód. Potomek si nicméně modifikátor klidně zavést může.
V Admineru chybí cizí klíč do vlastní tabulky proto, že buď se tabulka teprve vytváří (takže její jméno ještě není známé) nebo se může přejmenovat. Taky ještě nemusí existovat primární klíč. Dalo by se to vyřešit JavaScriptem, který by aktuální název tabulky do seznamu doplnil, ale kód by to zbytečně zkomplikovalo. Odkazy na sebe sama lze vytvořit pomocí obecných cizích klíčů (které jsou použitelné třeba i pro vytváření vícesloupcových klíčů nebo odkazů na neprimární klíč).
Juan:
Díky za odpověď. Co se týče Adminera, tak teď už důvody chápu. Já myslel, jestli se na něj třeba jen "nezapomnělo".K NotORM - nemyslel jsem konvenci user_id_created, ale např. modifikátor, který by bral řekněme jakýkoliv znak kromě podtržítka (jen pro příklad) a nazvu ho třeba %x.
Pak by přece šlo snadno zapsat konvenci %s_id_%x anebo třeba %x_by_%s (tedy user_id_created anebo created_by_user), atd. Žádnou jednotnou konvenci by to nevnucovalo, jen by to přineslo větší volnost.
Jakub Vrána :
Já tomu rozumím. Ale mě nepřijde příliš rozšířená ani obecná konvence, že se tabulka z názvu sloupce získá po vyhození něčeho.
Juan:
Mám další dotaz k NotORM. Při používání Dibi verze NotORM jsem narazil na následující problém:Pokud použiji zápis $db->table[$id] (možná se to může vyskytnou i v jiných situacích, nevím) pro výběr jednoho řádku a v Dibi mám nastaveno lazy = TRUE, skončím s chybou:
PHP Warning: mysql_real_escape_string() expects parameter 2 to be resource, null given...
Po troše pátrání jsem zjistil následující. Funkce quote (Result.php) vypadá takto:
<?php
protected function quote($string) {
return $this->notORM->connection->getDriver()->escape($string, dibi::TEXT);
}
?>
A protože máme aktivovaný lazy připojení, zápis $this->notORM->connection->getDriver() vrací nenastavené hodnoty. Zápis:
<?php
return $this->notORM->connection->escape($string, dibi::TEXT);
?>
sice funguje, ale je deprecated... Co s tím?
Jakub Vrána :
Zdá se, že je to už opravené na úrovni Dibi. getDriver() se nyní pokusí připojit.
Lweek:
Zdravím, chci se prosím pěkně zeptat, zda-li je možné přes NotORM propojit i dvě tabulky kde klíčový sloupce mají rozdílný název? Rád bych to totiž napasoval na již existující web, kde ale uživatelé mají klíčový sloupec [id] a tabulka kterou potřebuji napojit používá [id_user]. Používám Dibi verzi. Děkuji a přeji krásný den! Jakub Vrána :
Ano, lze to snadno. Postup je popsaný na http://www.notorm.com/#identifiers.
v6ak:
"NotORM uses the PDO driver to access the database."
To je, vzhledem k existenci Dibi verze, trošku nešikovná formulace na http://www.notorm.com/#examples . Celkově mi Dibi verze přijde taková schovaná, což je škoda.
Jakub Vrána :
Je to tak, snažím se upřednostnit verzi pro PDO.
v6ak:
Hmm, po bližším zkoumání mé nadšení trošku opadá. To je možná normální, ale hned řeknu, čím je to způsobeno.
NotORM_Result je ukázkové porušení SRP, protože reprezentuje jak filtrovanou tabulku, tak iterátor nad ní. Pokud chci vrátit iterator, musím použít clone. Je to snad podruhé, kdy jsem clone potřeboval.
Druhé nepříjemné zjištění bylo ve stejné třídě:
<?php
/** Count number of rows
* @return int
*/
function count() {
$this->execute();
return count($this->data);
}
?>
Pokud to chci použít pro stránkování, načítám zbytečně mnoho dat. Ale nevím, jak to obecně udělat efektivně. SELECT COUNT(*) FROM (SELECT ...) as t1 není v MySQL efektivní (na druhou stranu, možná je to efektivnější, než zmíněná implementace), trvá to dlouho. Nahradit sloupce v SELECT něčím jako COUNT(*) taky není ono, protože tam může být nějaká agregace. Na druhou stranu, je to možné v některých případech udělat, například při chybějícím seznamu sloupců.
v6ak:
Měl jsem to bufferovat a poslat najednou.
Chybí mi tu metoda setOrder, něco jako:
<?php
/** Set order clause and <strong>replaces all previous columns in order clause</strong>
* @param string for example "column1, column2 DESC"
* @return NotORM_Result fluent interface
*/
function setOrder($columns) {
$this->order = array($columns);
return $this;
}
?>
Nechceš to, prosím, commitnout do Result.php?
Jakub Vrána :
Uveď prosím nějakou ukázku využití.
v6ak:
Pokud chci implementovat setSorting v http://github.com/janmarek/Gridito/blob/mas…/IModel.php , tak se bez toho těžko obejdu.
Jakub Vrána :
Chci API zachovat co nejjednodušší. Co kdyby tedy metoda order() třídění nastavila? Je vůbec někdy potřeba do něj něco přidávat?
v6ak:
Hmm, na druhou stranu, byl by to IMHO celkem zbytečný BC break.
Jakub Vrána :
Projekt je v celkem rané fázi, takže mě to moc netrápí. Navíc bych alespoň zjistil, jestli vůbec někdo opakované volání order() používá a pokud ano, tak k čemu.
v6ak:
Jak to vlastně je v případě těch agregací? Zvažuji implementaci s COUNT(*). V nejjednodušší formě by to zlobilo asi jen bez group by a s nějakým agregovaným sloupcem, protože stávající implementace vrací v takovém případě 1, zatímco nová by vracela celkový počet řádků. Podobně by to dopadlo, kdybychom sloupec count(*) přidali.
Na druhou stranu, těžko si tu dovedu představit, kde by to mohlo vadit. Je to jen mou nedostatečnou představivostí a agregační funkce nad celou tabulkou mají smysl (popř. je tu jiný případ, na který jsem zapomněl), nebo to opravdu reálně vadit nemůže?
Jakub Vrána :
Metoda count() původně byla namapovaná právě na COUNT(*), ale problém nastal v případě, kdy jsem chtěl jednak zjistit celkový počet řádek a jednak potom s výsledkem i pracovat (což je poměrně běžné). V takovém případě se zbytečně kladly dva dotazy. Proto jsem count() zjednodušil na současné přímočaré řešení.
Když chceš zjistit samotný počet, vždycky můžeš zavolat $table->group("COUNT(*)"), což i považuji za čistší řešení.
v6ak:
Hmm, já to vidím jinak. Nejdřív zjistím počet, pak přidám limit a offset a zjistím si data pro jednu stránku. Takto nejdříve načtu všechna data jen kvůli počtu a pak načtu data pro jednu stránku.
Jakub Vrána :
Vždyť ten počet pro jednu stránku můžeš snadno zjistit pomocí group("COUNT(*)").
v6ak:
Jasně, už jsem to tak přepsal. Mimochodem, díky za tip. Jen jsem rozebíral použití. Většinou nepotřebuji znát počet výsledků, ale spíš celkový počet pro stránkování. Nějaká metoda by se na to hodila.
Jakub Vrána :
Popiš mi prosím situaci, v které potřebuješ vrátit iterátor a ukaž to použití clone.
v6ak:
Při implementaci http://github.com/janmarek/Gridito/blob/mas…/IModel.php v metodě getIterator:
<?php
public function getIterator() {
return clone $this->table;
}
?>
Nevím proč, ale z použití clone mám vždy takový divný pocit. Aspoň pokud se pro něj rozhodnu já.
Ta třída NotORM_Result by se dala rozdělit i na tři. NotORM_Table, NotORM_Query a NotORM_Result.
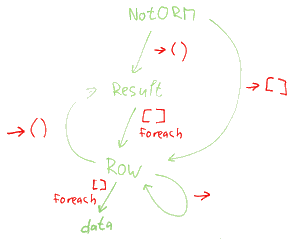
Jakub Vrána :
Můžeš to rozdělení prosím trochu víc rozebrat? Co by kdo vracel, jak by to bylo propojené? Třeba ve stylu obrázku u tohoto článku.
v6ak:
http://www.q3.cz/view.php?filename=57NotORM.png
Některé zřejmé věci jako třeba metody z iterátoru, __call u NotORM nebo implementaci některých rozhraní jsem tam nedával. Třídy NotORM_Row by se to asi nedotklo. Metody insets a update jsou návrh. Update je možná trošku zvláštně navrženo, protože některé vlastnosti selectu by se tam neuplatnily (např. výčet sloupců). Celkově jsem tyto metody myslel spíše pro ilustraci logiky než jako něco, co je určitě potřeba implementovat.
Všimni si metod count. Count na tabulce by vracel všechny z tabulky, count z Table by se týkal celé tabulky, count z Query by se týkal dotazu v aktuálním stavu (a mohl by tedy použít ono COUNT(*)) a count z Result by se týkal vrácených dat, takže by mohl použit něco jako count($this->data).
ArrayAccess z Result jsem nepochopil, takže jsem to vynechal, ale asi by to zůstalo v Resultu.
Jakub Vrána :
Tomu náčrtku příliš nerozumím. Když bych zavolal $db->table(), tak by se mi vrátilo NotORM_Table? Takže abych mohl zavolat order(), musel bych psát $db->table()->select()->order()? To se mi nelíbí.
Všiml sis komentáře u implementace Iteratoru ve zdrojáku Result? Je použit místo IteratorAggregate proto, že iterovaná data se mohou v průběhu iterace změnit (konkrétně myslím v MultiResult). Externí iterátor by se s tím vypořádal těžko.
ArrayAccess složí k získání jednoho konkrétního záznamu. $db->table[5] je zkratka za $db->table("id", 5)->fetch().
Současná implementace ukládání je popsaná na http://www.notorm.com/#persistence.
Celkově vzato v rozdělení třídy nevidím nějaký praktický užitek, takže se do něj pouštět nebudu.
v6ak:
Myslím, že to chápeš správně.
NotORM může být použito různě, například:
* jako základ jiné knihovny, někdo tu vtipkoval o NotORMORM
* nejjednodušším způsobem, jak je v příkladech
* samotné dotazy v nějaké extra třídě, ale s výsledky je pracováno přímo v šabloně pomocí foreach apod.
V případě nejjednoduššího použití toto rozdělení programátor téměř nepocítí, pokud vůbec. V ostatních případech většinou ano. Například, v jednom projektu máme ke každému logickému celku (ne tabulce) třídu, která ví, jak dotazovat databázi, a výsledek vrací často v nezměněné formě. V některých případech s výsledkem i nějak pracuje a dělá mírnou abstrakci. Je to v současnosti zalořené na Dibi. Já si představoval přepis s použitím NotORM. Mezi výhody patří třeba zmizení otravných (a neefektivních) joinů. Další věc, která se mi na DibiFluent, které je tam často použito, nelíbí, je uvádění tabulky až někdy později (ve from()). To je otravné i v nadstavbách nad Dibi. Měl jsem takovou představu, že bych v těch třídách se na jednotlivé tabulky obracel přes self::$name a měl nějakou statickou vlastnost $name, která by obsahovla NotORM_Table. Byl jsem požádán, aby tabulky byly prefixovány podle onoho logického celku. Toto řešení by 1) ušetšino nutnost psát pokaždé prefix (self::$dbh->prefix_name vs. self::$name) 2) umožnilo snadno přejmenovat tabulky, na jejichž prefixování předchozí programátor kašlal. Obecně, v kontextu třídy to vlastně umožňuje udělat krátký alias tabulky, něco jako use \Foo\Goo\GogoBar as Bar;.
U současné koncepce to takto nejde. Uložil-li bych tam instanci NotORM_Result, pak bych si nejbližším voláním metody s touto tabulkou pracující změnil stav této proměnné tak, že další volání metod pracujících s touto tabulkou by patrně nefungovaly korektně.
K ->select() navíc: je to ještě trošku zvyk z DibiFluent, že prvně určím operaci a potom podrobnosti (where apod.). Takže ano, tak, jak jsem to navrhl, by to nutné bylo. Ale, na druhou stranu, není to problém upravit. Celkem čistě, bez __call a bez psaní zrcadlících metod:
* Přidáme NotORM_AbstractQueryable.
* Tato třída bude obsahovat metody jako select, order, where apod.
* Tyto metody budou vracet vždy NotORM_Query.
* Tyto metody budou pracovat s instancí NotORM_Query, která jim bude poskytnuta přes abstraktní metodu, řekněme, provideQuery().
* Z této třídy bude dědit NotORM_Table (metoda provideQuery() bude vracet novou instanci NotORM_Query) a NotORM_Query (metoda provideQuery() bude obsahovat prostě jen return $this).
Příklad implementace metody NotORM_AbstractQueryable::limit:
<?php
function limit($limit, $offset = null) {
$q = $this->provideQuery()
$q->limit = $limit;
$q->offset = $offset;
return $q;
}
?>
Třída NotORM_AbstractQueryable by byla "package-private" - jako taková by nebyla součástí veřejného API, takže by bylo chybou z ní dědit v jiné třídě než v třídách knihovny NotORM.
Mimochodem, jeden detail k názvům: Nešlo by NotORM nahradit za NotOrm? Je to podle některých konvencí (Zend a asi i PEAR) a funguje to lépe s doplňováním.
Poznámky o změně dat v průběhu iterace jsem si všiml, ale nepochopil. Jak se během iterace mohou měnit data a jaké to má využití?
* Provedení nového dotazu? Využití si představit nedovedu a stejně by bylo nutno iterovat od začátku.
* Nějaké unset apod? To by mimochodem s odděleným iterátorem nebyl problém.
Implementace ArrayAccess je pak asi k AbstractQueryable.
K perzistenci: Zajímavé, jen to vypadá, že to bude číst data, i když není potřeba.
Jakub Vrána :
Všemu tomu dlouhému zdůvodnění příliš nerozumím. Ale když mi pošleš patch, který zachová stávající API (které považuji za nejcennější) a přitom kód rozstrká do více tříd, tak se na to přinejmenším podívám. Ideální mechanismus k tomu je fork na GitHubu.
Pojmenování NotOrm by mi taky bylo bližší, ale konvence bývá spíš s velkými písmeny. Rozhodně u PDO, které NotORM používá, takže je vhodné zůstat konzistentní. PEAR se taky píše velkými písmeny.
Co se iterace týče, tak to souvisí s omezením získávaných sloupců jen na ty použité. Když se v průběhu iterace zjistí, že nějaký sloupec není načtený, tak se položí nový dotaz a dotáhnou se všechny sloupce.
Perzistence: Metody update() a delete() se dají volat i nad NotORM_Result, kdy se žádný SELECT nepoloží. Takže žádná data se zbytečně nečtou.
v6ak:
K pojmenování: Namátkou třeba Zend_Db_Xml_XmlContent nebo Zend_Db_Xml_XmlUtil ze ZF. Ale pravda, s tím PEARem jsem se mýlil:
* http://pear.php.net/package/XML_Parser/redirected
* http://pear.php.net/manual/en/standards.naming.php
U Nette jsem sice naming conventions neviděl, ale směřování jde vidět příklad na http://api.nette.org/1.0/Nette-Web/Html.html - v tomto směru shodně s ZF.
Po praktické stránce: některá IDE nabízejí zajímavé možnosti doplňování, například pod ZDXXU, ZeDXmXmUt apod. je možné najít Zend_Db_Xml_XmlUtil, přičemž jsou jsou právě velká písmena podstatná pro chování těchto funkcí podstatná. U tříd NotORM je nutné začít s NORM, takto by stačilo jen NO.
Zachovat API do posledního detailu nechci, ale v případě jednoduchých použití (jako je v příkladech) by to nemělo znamenat přepisování kódu. Nešly by některé podivné operace, například v průběhu iterace nad výsledkem volat metody měnící dotaz, dotaz následně vykonat a najednou iterovat nad jinými daty.
K iteraci a IteratorAggregate: OK, v tom nevidím problém.
K perzistenci: OK, to vypadá dobře.
K forku: Čekal jsem to, ale chtěl jsem o tom prvně diskutovat. No, mám mnoho věcí, které bych mohl udělat a i nějaké, které bych měl udělat, tak uvidíme. Teď jdu na jednu věc, kterou mám udělat do středy.
Jakub Vrána :
Co se jmenných konvencí týče, tak s tebou souhlasím. Jak jsem psal, NotOrm mi je taky bližší. Ale PDO to má prostě jinak.
Zakázání podivných operací by nevadilo, na fork se těším.
Phoenix:
Jak bych měl prosím slepit dohromady větve update a dibi? Chci používat na pozadí dibi a zároveň mít možnost používat insert, update v NotORM. (Položil jsem stejný dotaz na Zdrojáku: http://forum.zdrojak.root.cz/index.php?topic=216.msg722;topicseen, zatím bez odpovědi, tak se ptám i tady) Jakub Vrána :
Můžeš zkusit použít merge. Ale já se do toho pouštět nebudu, protože Dibi má podle mě samo o sobě dost jednoduchý způsob modifikace dat. Jo a branch update byl sloučen do master.
Phoenix:
Děkuji za reakci! :-) OK, zůstanu raději dál přímo u dibi.Olda Šálek:
Ahoj, jen taková drobnost.
Jak zjistím použité dotazy? Rád bych buď nějak aktivoval debug mód (každý provedený dostaz se mi vypíše) nebo alespoň sql dotazy logovat a vypsat na konci stránky.
Jakub Vrána :
Slouží k tomu $notorm->debug. http://www.notorm.com/#api
Olda Šálek:
Díky, ale to jsem v API našel. Při debug = true;
Notice Use of undefined constant STDERR - assumed 'STDERR'.
debug = 'dump'; mi funguje. Ale to ne nevypíše dobu trvání SQL dotazu, neobarví SQL dotaz… jdu hledat, jaké jsou možnosti s propojení na nette, jeho debug bar, profiler a spolupráce s dibi.
Každopádně klobouk dolů, 3 SQL dotazy jsou rychlejší, než optimalizované JOIN spojení více tabulek.
Jakub Vrána :
debug = true je určeno pro spuštění z příkazového řádku, kde je konstanta STDERR definovaná.
Panel do Nette Debug baru mám připravený, zveřejním ho příští týden při školení http://php.vrana.cz/skoleni-jak-vytvarim-webove-aplikace.php. Spolupráci s Dibi momentálně předělávám v branchi storage, ale nemám k tomu moc velkou motivaci, protože jsem ještě od nikoho nezjistil, na co Dibi při použití NotORM vlastně použije a jakou to má výhodu proti PDO.
Michal Prynych:
Škoda, že v jednom souboru je více tříd, trošku to komplikuje začlenění do existujícího frameworku. Také by mě zajímalo, co vás přimělo pojmenovat třídu NotORM místo NotOrm - v knize píšete, že malá písmenka máte radši, i já to tak mám :) Jakub Vrána :
Rozhodl jsem se tak proto, že NotORM v konstruktoru přijímá objekt třídy PDO, který je zvykem psát právě takhle.
Matěj Konečný:
Omlouvám se, že se ptám tady, ale nenašel jsem nikde žádnou diskusní skupinu věnující se NotORM. Potřebuji s NotORM položit dotaz využívající fulltext a chci výsledky seřadit podle hodnoty vrácené MATCH..AGAINST. Kód vypadá následovně:<?php
$db->objekty()->select('object_id, name')
->where('MATCH(name) AGAINST (? IN BOOLEAN MODE)', $searchTerm)
->order('MATCH(name) AGAINST ("'.addslashes($searchTerm).'") DESC');
?>
Dá se nějak orderu také přidat parametr? Popřípadě jak mám vstupní řetězec escapovat?
Jakub Vrána :
Ptáš se na správném místě, diskusní skupina zatím neexistuje.
Taky už jsem na podobný problém narazil. Správně bys měl použít $pdo->quote: $pdo se předává konstruktoru NotORM, takže ho máš k dispozici. Ale chápu, že je to poněkud nepohodlné, protože $pdo není skoro na nic potřeba, takže ho lze po zavolání konstruktoru NotORM většinou zahodit. Nenapadá mě ale, co s tím – $notORM->quote() slouží pro přístup k tabulce quote, $notORM->$table()->quote() by zveřejnit šlo, ale API nedává smysl. Nějaký nápad?
Matěj Konečný:
Použil jsem $pdo->quote(), ale měl jsem dojem, že to quotuje nějak blbě. Což, jak se teď koukám, byl dojem špatný. Co se řešení týče, možná by stačilo dát PDO jako veřejnou propertu ($db->pdo), protože takhle je řešený debug mód, transakce atd. ($db->transaction = 'BEGIN'...). Případně vytvořit třídu NotORM_QuotedParam nebo tak nějak - po vzoru NotORM_Literal.. Jakub Vrána :
Vlastnosti v NotORM jsou write-only, $db->pdo[1] čte z tabulky pdo záznam s ID 1. Je to spíš akademický problém, ale chtěl bych najít nějaké lepší řešení. NotORM_QuotedParam by musel v konstruktoru dostávat instanci PDO nebo NotORM, což je pakárna.
v6ak:
No je to daň za to cool API.
S QuotedParam problém nevidím. Pokud si představím návrh s Composite, stačí, aby tyto 'cihličky' dostávaly do parametrů dostatek informací.
Matěj Konečný:
Možná při zavolání konstruktoru specifikovat název metody, která bude použita pro quotování? Anebo nešly by umožnit patametry i u jiných klauzulí než where? Jakub Vrána :
S těmi dalšími parametry to nepůjde tak snadno, protože už jsou zabrané pro order('col1', 'col2'). Ale co kdyby to bylo takhle?
<?php
$result->order(new NotORM_Literal('MATCH(name) AGAINST (?) DESC', $searchTerm));
?>
To by se zároveň dalo použít i při vkládání, kde jsem to potřeboval já:
<?php
$result->insert(array(
"date" => new NotORM_Literal('STR_TO_DATE(?, ?)', $date, $format),
));
?>
Jakub Vrána :
Hotovo v Gitu.
Matěj Konečný:
Kdesi (na nette fóru) jsem našel požadavek na fetchAll() (alespoň jestli se nepletu) a byl zamítnut, že se to dá vyřešit zavoláním iterator_to_array($tb). Mně ovšem iterator_to_array() vrací ne pole pouze hodnot tabulky, ale je tam plno přebytečných dat. Což je docela problém, když chci pole rovnou vytisknout pro javascript (json_encode()). Dělám nějakou chybu? Nebo bylo nalezené info už zastaralé? Teď mám v kódu plnokrát foreach. Jakub Vrána :
Pokud chceš pole asociativních polí, tak budeš muset zavolat <?php array_map('iterator_to_array', iterator_to_array($result)); ?>.
Příště by pomohlo, kdybys místo „plno přebytečných dat“ lépe napsal, co přesně voláš, co přesně dostaneš a co bys dostat chtěl.
SEO Konzultant:
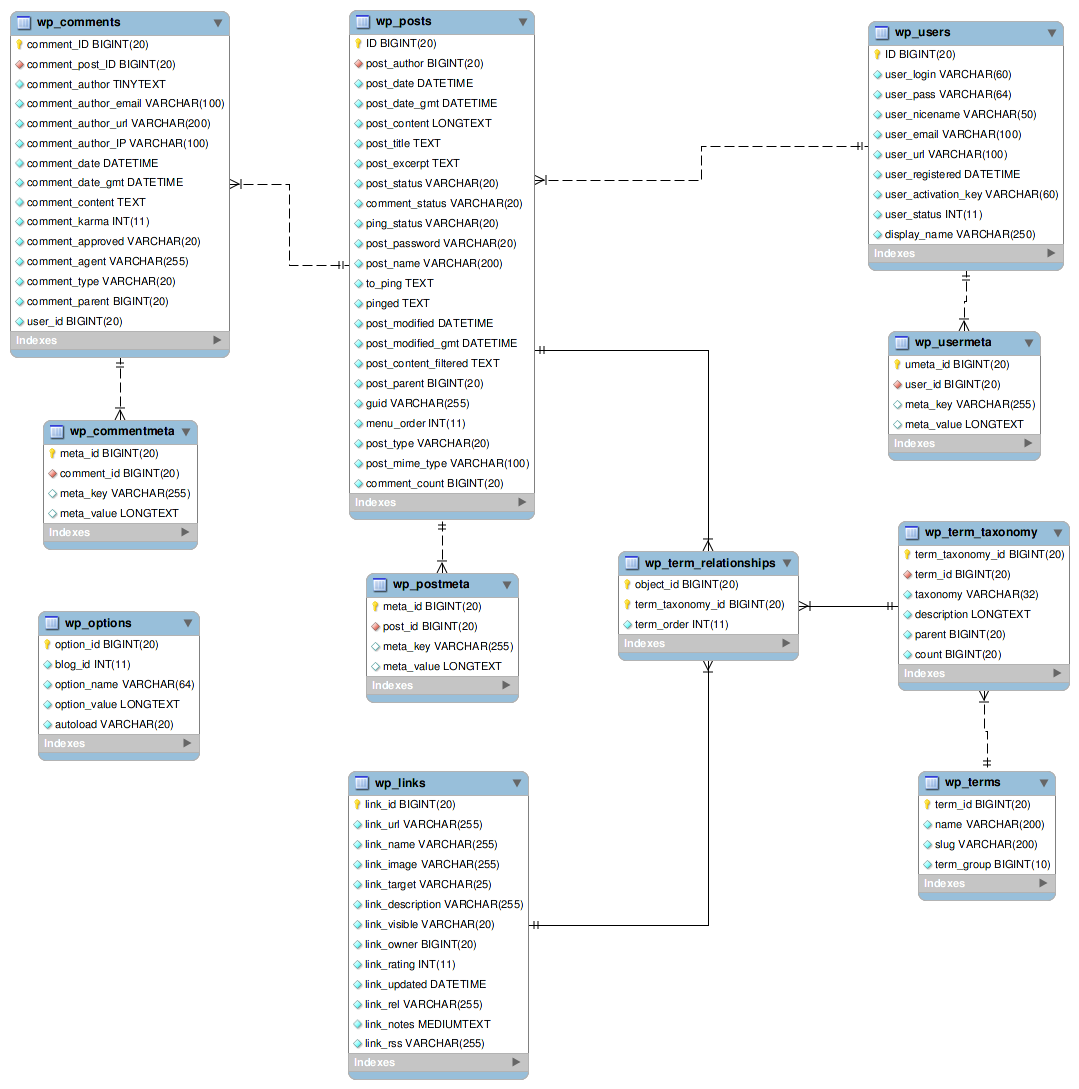
Ahoj, koukám na notorm a přemýšlím, jestli se to dá využít třeba u wordpressu, resp. co bych musel všechno upravit. Tam mají totiž jednak tabulky nějaký prefix a navíc je tam míchán ten plurál a singulár (plus navíc nějaké pluginy to mají úplně blbě) a jindy se zas používá stejný název sloupce. Viz http://codex.wordpress.org/images/9/9e/WP3.0-ERD.png
Tj. otázka je, jestli to jde nějak na začátku nastavit podle těchto známých vazeb
Ahoj
Tomáš Kapler
Jakub Vrána :
Tak tomu říkám bordel… To v tom nemají žádný systém? Možnosti jsou dvě: buď použít NotORM_Structure_Discovery nebo podědit NotORM_Structure_Convention zhruba takhle (jen naznačuji):
<?php
class WpStructure extends NotORM_Structure_Convention {
protected $prefix = 'wp_';
protected $table = '%ss';
function getPrimary($table) {
switch ($table) {
case "comment": return $table . "_ID";
case "commentmeta": return "meta_id";
case "usermeta": return "umeta_id";
}
return parent::getPrimary($table);
}
function getReferencedColumn($name, $table) {
if ($table == "comment" && $name == "post") {
return "comment_post_ID";
}
return parent::getReferencedColumn($name, $table);
}
function getReferencedTable($name, $table) {
if ($name == "commentmeta") {
return "$this->prefix$name";
}
return parent::getReferencedTable($name, $table);
}
}
?>
Schmutzka:
Kdybyste někdo náhodou hledali, jak nastavit UTF-8 charset: "http://www.laszlo.nu/post/34159352/how-to-…-objects-pdo"
Schmutzka:
Mám problém s update. Mám tabulku categories, kde vezmu záznam s id = 33 a chci změnit pořadí z 25 na 12. Toto mi ale nefunguje. Podle http://www.notorm.com/#persistence by mělo, jestli jsem něco nepřehlédl.
$row = $db->categories[33];
dump($row["order"]);
$row->update(array("order" => 12));
Nevím kde dělám chybu, zkoušel jsem vše možné. Děkuji za help.
Jakub Vrána :
Problém bude s tím, že ORDER je klíčové slovo. Viz http://www.notorm.com/#faq
Dá se to vyřešit vlastním ošetřením sloupce, ale doporučuji spíš sloupec přejmenovat třeba na rank.
V obdobných případech pomůže zapnout $db->debug nebo nastavit hlášení chyb v PDO.
Schmutzka:
To jsem teda idiot. Díky.
$db->debug jsem zkoušel a házelo to pro mne neznámé chyby.
(Nešlo by v admineru ošetřovat názvy sloupců skrze filtr klíčových slov? :))
Jakub Vrána :
Adminer by měl zvládnout všechno, co zvládne databáze. Klíčová slova se dají použít, pokud jsou ošetřena (což Adminer dělá), takže je nelze zakázat.
Michal:
Nevím jestli to patří přímo sem, ale nezdá se mi že by to patřilo do fóra k notORM na google groups, protože píšu česky.Jak jsou udělané na webu notorm ty záložky s hlavním obsahem a adresou v url za hashem? Je to vaše řešení nebo to je někde dostupné ? Děkuji.
Michal:
Ha, tak to mě nenapadlo, že to je to samé když jsem to tam hledal :-DPetr Ogurčák:
Můžu se zeptat, kde je chyba, že z tohoto kódu
<?php
$product = BaseModel::fetchAll('product')->where("id", $product_id)->select("IF(newprice,newprice,price) AS price");
?>
dostávám takovýto sql dotaz
<?php
SELECT IF(newprice,newprice,price) AS price FROM product WHERE (id = 16) AND (id = 'price')
?>
Děkuju
Petr Ogurčák:
ještě metoda BaseModel::fetchAll()
<?php
static function fetchAll($table) {
return self::$notORM->{$table};
}
?>
Jakub Vrána :
Takové chování nepozoruji.
Petr Ogurčák:
byla to triviální chyba.. chyběl tam fetch()Petr Ogurčák:
ale narazil jsem na ještě jeden problém a to při pokusu updatovat řádek v tabulce s M:N vztahem..pokusil jsem se přepsat do vzorového příkladu
<?php
foreach($application->application_tag() as $application_tag) {
$application_tag->update(array('neco'=>5,'necojineho'=>4));
}
?>
vyžaduje to mít primární klíč id..zde je primarni klic kombinaci application_id,tag_id ..
je chyba někde u mě? nebo je toto požadované chování?
Petr Ogurčák:
Pokud dám spojovací tabulce ještě primární klíč id..tak to funguje.. ale pokud je primární klíč kombinací application_id a tag_id.. tak to přesto hledá sloupec id
Jakub Vrána :
Tohle není podporované. Je potřeba to napsat takhle:
<?php
$db->application_tag('application_id', $application['id'])->update(array());
?>
Marek Šnebeger:
Ahoj, mám tabulku users a sloupce uploaded, downloaded. Sloupce jsou typu bigint a je v nich uloženo, kolik bajtů uživatel stáhnul / nahrál. Jak mám ale v notorm zapsat update tabulky tak, aby se mi stažená / nahraná data přičetli k existujícímu číslu? Moc díky za pomocPetr Ogurčák:
Myslím, že využít Literal ..viz APIThe $array parameter holds column names in keys and data in values. Values are automatically quoted, SQL literals can be passed as objects of class NotORM_Literal, for example:
<?php
$array = array(
"title" => "NotORM",
"author_id" => null,
"created" => new NotORM_Literal("NOW()"),
);
?>
NotORM_Literal also accepts question marks and parameters: new NotORM_Literal("NOW() - INTERVAL ? DAY", $days).
Marek Šnebeger:
<?php$user->update( array(
"downloaded" => new NotORM_Literal( "downloaded+$downloaded" ),
"uploaded" => new NotORM_Literal( "uploaded+$uploaded" ),
));
?>
Takhle to funguje, tisíceré díky :)
Petr Ogurčák:
rádo se stalo
Filip Halaxa:
Tento zápis by mohl být náchylný na SQL injection. Lepší je:<?php
$user->update( array(
"downloaded" => new NotORM_Literal( "downloaded+?", $downloaded),
"uploaded" => new NotORM_Literal( "uploaded+?", $uploaded),
));
?>
 rotten77:
rotten77:
Zdravím,
mám problém s NotORM na hostingu OneBit. K databázi lze přistupovat jenom přes IP adresu - "127.0.0.1", ale NotORM (nebo PDO?) to automaticky převádí na "localhost" a tím pádem se nejde k databázi připojit (MySQL). Neví někdo, jak tohle vyřešit/obejít?
rotten77:
Chyba byla zde
<?php
$connection = new PDO("mysql:dbname=databaze;hostname=127.0.0.1; ...
?>
stačilo přepsat "hostname" na "host"
Miloš Brecher:
NotORM jsem nasadil na pár projektů a jsem velmi spokojen. Jenom při chybě se vypíše PDO hláška k sql dotazu zkonstruovanému uvnitř NotORMu a musím ručně dohledat řádek ve zdrojovém kódu PHP kde chyba fakticky vznikla. Nedalo by se toto nějak inovovat?Diskuse je zrušena z důvodu spamu.

{kind=link}
{kind=link}