Srovnání dotazů do závislých tabulek
Když chceme získat data z hlavní tabulky a k tomu z několika vedlejších, máme v zásadě tři možnosti, kolika dotazy to udělat:
- Položit jeden komplexní dotaz
- Položit konstantní počet dotazů (pro každou tabulku jeden)
- Položit více dotazů (např. jeden dotaz pro každý záznam v hlavní tabulce)
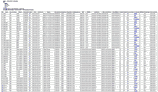
Obecně se má za to, že počet dotazů do databáze by měl být co nejnižší, a první řešení je tedy nejlepší s jedinou nevýhodou – komplikovanými dotazy. Kromě minimalizace počtu dotazů jde ale při komunikaci s databází i o to, kolik se přenáší dat. U prvního řešení se vždy znovu přenáší i data, která už máme (pro každý řádek ze závislé tabulky se znovu přenáší i data z hlavní tabulky), naproti tomu u druhého řešení se přenáší všechna data kromě primárních klíčů jen jednou. Ilustrují to následující obrázky zachycující všechny položené dotazy a jejich výsledky:
| Jeden dotaz | Konstantní počet | Více dotazů |
|---|---|---|
 |
 |
 |
Obrázky jsou záměrně hodně zmenšené, ale je na nich vidět jak počet položených dotazů, tak objem přenesených dat.
Zajímalo mě, jak jsou na tom jednotlivé varianty výkonnostně. Z databáze World jsem chtěl získat prvních deset měst spolu se státy, do kterých patří, a jazyky, kterými se v nich mluví.
Jeden dotaz
Získat všechna data jedním dotazem není právě triviální. Chceme jen prvních deset měst, ale k nim všechny jazyky, pro omezení počtu měst tedy potřebujeme poddotaz. Průchod výsledkem taky není zrovna intuitivní – v cyklu musíme detekovat, jestli se změnilo město nebo jestli pořád ještě vypisujeme jazyky aktuálního státu:
<?php $result = mysql_query(" SELECT *, Country.Name AS CountryName FROM ( SELECT * FROM City ORDER BY ID LIMIT 10 ) AS City INNER JOIN Country ON City.CountryCode = Country.Code INNER JOIN CountryLanguage ON City.CountryCode = CountryLanguage.CountryCode "); $city_id = 0; while ($row = mysql_fetch_assoc($result)) { if ($city_id != $row["ID"]) { echo "$row[Name] ($row[CountryName])\n"; $city_id = $row["ID"]; } echo "- $row[Language]\n"; } ?>
Konstantní počet dotazů
U druhého přístupu jsou dotazy jednoduché, složitá je ale logika okolo – nejprve musíme zjistit, jaká data vlastně chceme získat, a následně je uložit do strukturovaných polí:
<?php $cities = array(); $countries = array(); $result = mysql_query("SELECT * FROM City ORDER BY ID LIMIT 10"); while ($row = mysql_fetch_assoc($result)) { $cities[] = $row; $countries[$row["CountryCode"]] = array(); } $result = mysql_query("SELECT * FROM Country WHERE Code IN ('" . implode("', '", array_keys($countries)) . "')"); while ($row = mysql_fetch_assoc($result)) { $countries[$row["Code"]] = $row; } $languages = array(); $result = mysql_query("SELECT * FROM CountryLanguage WHERE CountryCode IN ('" . implode("', '", array_keys($countries)) . "')"); while ($row = mysql_fetch_assoc($result)) { $languages[$row["CountryCode"]][] = $row; } foreach ($cities as $city) { echo "$city[Name] (" . $countries[$city["CountryCode"]]["Name"] . ")\n"; foreach ($languages[$city["CountryCode"]] as $language) { echo "- $language[Language]\n"; } } ?>
Logika je komplikovaná, z hlavního kódu se ale dá přesunout do knihovny.
Více dotazů
Třetí přístup je přímočarý:
<?php $result = mysql_query("SELECT * FROM City ORDER BY ID LIMIT 10"); while ($row = mysql_fetch_assoc($result)) { $country = mysql_fetch_assoc(mysql_query("SELECT * FROM Country WHERE Code = '$row[CountryCode]'")); echo "$row[Name] ($country[Name])\n"; $result1 = mysql_query("SELECT * FROM CountryLanguage WHERE CountryCode = '$row[CountryCode]'"); while ($row1 = mysql_fetch_assoc($result1)) { echo "- $row1[Language]\n"; } } ?>
Srovnání
Tabulky jsou typu MyISAM, všechny dotazy se vyhodnocovaly efektivně (s využitím indexů). Rozdíly ve výsledcích by tedy měly být způsobeny především režií přenosů.
| Podmínky | Jeden dotaz | Konstantní počet | Více dotazů |
|---|---|---|---|
| Vzdálený server (MySQL 5.0.32), bez SQL keše, všechny sloupce | 3,37 | 2,68 | 18,87 |
| Vzdálený server, bez SQL keše, jen vybrané sloupce | 1,83 | 2,67 | 18,50 |
| Vzdálený server, se SQL keší, všechny sloupce | 2,19 | 2,61 | 18,31 |
| Lokální server (MySQL 5.1.26), bez SQL keše, všechny sloupce | 1,59 | 0,72 | 3,96 |
| Lokální server, bez SQL keše, jen vybrané sloupce | 0,68 | 0,63 | 2,66 |
Všechny časy jsou v sekundách na tisíc spuštění (jde o syntetický test bez paralelního přístupu), jedná se o medián ze tří spuštění.
- Zapnutí SQL keše příliš nepomohlo přístupu s více dotazy – pro zrychlení tohoto přístupu by keš musela být přímo v aplikaci.
- Omezením sloupců z
*jen na ty použité se zásadně zmenšil objem přenášených dat u jednoho dotazu a tím se zvýšila i jeho rychlost. Příklad ale využívá vlastně jen identifikátor a název, což v praxi nebývá příliš obvyklé (obzvlášť z hlavní tabulky je obvykle potřeba více dat).
Závěr
Potvrdila se má myšlenka, že objem přenášených dat bude mít na rychlost obdobný vliv jako počet dotazů. Pokud je dat málo, je nejrychlejší jeden dotaz (proti kterému hraje jeho složitost), pokud je jich hodně, je nejrychlejší konstantní počet (proti kterému hraje složitost kódu). Více dotazů je ve všech případech řádově pomalejší.
V určitých případech můžeme dotaz zjednodušit a objem přenášených dat snížit např. použitím funkce GROUP_CONCAT. Může to ale znamenat těžko přípustné přenesení prezentační logiky přímo do SQL dotazu.
Přijďte si o tomto tématu popovídat na školení Konfigurace a výkonnost MySQL.
Diskuse
pepak:
Ten test má ovšem kromě drobného nedostatku, že totiž nezohleďnuje složitost dotazů (jakmile kterýkoliv z těch dotazů má obsahovat něco složitějšího než jen prostý výběr políček z jedné tabulky, začne se pořadí dramaticky měnit; pokud dojde na UNIONy, subselecty nebo i pouhé agregace, je často výhodnější rozdělit dotaz na víc menších dotazů) i jeden zásadní nedostatek: Dotazy stavěné tak, jak jsou v příkladu, z podstaty věci silně penalizují dělení na víc poddotazů. Ten test měl být dělán s připravenými dotazy, do kterých se jenom dosazují parametry (SELECT * FROM tabulka WHERE cizi_klic=?) - pak by se nejspíš (záleží na databázi) pořadí velice srovnalo a hlavní roli by začala hrát složitost těch jednotlivých dotazů a množství přenášených dat. Jakub Vrána
Jakub Vrána  :
:
V článku je jasně uvedeno, že se všechny dotazy vyhodnocovaly efektivně (s využitím indexů). I složité dotazy se často dají napsat tak, aby se vyhodnotily efektivně – pokud by tomu tak nebylo, je v první řadě samozřejmě nutné dotazy zefektivnit.
Pochop, že test se věnuje náročnosti komunikace s databází, nikoliv náročnosti dotazů.
Připravené dotazy třetímu řešení vůbec nepomohou. Jeho hlavním nedostatkem je totiž vysoký počet komunikací s databází. Připravené dotazy sníží objem přenesených dat, ale počet round-tripů naopak zvýší. Přesně v souladu s mým očekáváním se čas při použití připravených dotazů (vzdálený server, bez SQL keše, jen vybrané sloupce) zvýšil na 19,93.
<?php
$stmt = $db->prepare("SELECT Name FROM Country WHERE Code = ?");
$stmt->bind_param("s", $countryCode);
$stmt->bind_result($countryName);
$stmt1 = $db->prepare("SELECT Language FROM CountryLanguage WHERE CountryCode = ?");
$stmt1->bind_param("s", $countryCode);
$stmt1->bind_result($language);
$result = $db->query("SELECT Name, CountryCode FROM City ORDER BY ID LIMIT 10");
while ($row = $result->fetch_assoc()) {
$countryCode = $row["CountryCode"];
$stmt->execute();
$stmt->store_result();
$stmt->fetch();
echo "$row[Name] ($countryName)\n";
$stmt1->execute();
$stmt1->store_result();
while ($stmt1->fetch()) {
echo "- $language\n";
}
}
$stmt->close();
$stmt1->close();
?>
A ještě k tomu poučování, jak měl být test dělán – test prostě porovnal tři nejobvyklejší způsoby řešení tohoto problému. Nahradit některý z nich jiným by byla chyba.
shortboy:
Podle mě zajímavé srovnání, pouze bych navrhoval počítat prostý průměr ze tří naměřených hodnot místo použitého mediánu. Jakub Vrána :
Medián se používá proto, že některé měření může ustřelit (typicky první, než se server probere a uvědomí si, že po něm něco chceme). Průměr by to zbytečně kazilo, medián o typickém průběhu bude vypovídat lépe.
Ale zrovna v tomto měření si byly všechny tři měřené hodnoty tak blízko, že to vyjde nastejno.
fos4:
Test byl měřen s SQL_NO_CACHE, takže výsledky 3 měření by měli být plus mínus stejné.David:
Díky za článek, nakopl mě... :-)Megaloman:
Položit komplexní dotaz je správná volba, ale argumenty proti němu v článku nejsou správné:ad "...první řešení je tedy nejlepší s jedinou nevýhodou – komplikovanými dotazy."
Pokud je pro někoho komplikované spojit několik tabulek, tak s SQL buď začíná, nebo je amatér, který něco zbastlí tak, ať to funguje, bez zájmu o výkonnostní hledisko. Případně za vehementního předstírání zájmu a ospravedlnění svého amatérismu tímto článkem: Na localhostu je to přece rychlejší!
ad "Kromě minimalizace počtu dotazů jde ale při komunikaci s databází i o to, kolik se přenáší dat..."
Přenos dat se dá minimalizovat vyjmenováním sloupců, které chci mít ve výsledku, ne jen tupě používat SELECT * FROM ..., co ostatně potvrzuje výsledek 2. výkonnostního testu.
Prosazování jakéhokoli jiného přístupu než s komplexním dotazem mi přijde jako neznalost/neschopnost/nepochopení základních možností spojování tabulek v jazyce SQL a smyslu normalizace dat.
Jakub Vrána :
Komplexní dotaz je samozřejmě správná volba, ale ne jediná správná a má i své nevýhody. Sestavit komplexní dotaz je totiž pracné a dál ho rozšiřovat ještě pracnější.
V článku je uvedeno, že příklad je umělý v tom, že přenáší minimum sloupců (jen ID a název). Je to tak proto, aby byly výsledky co nejkontrastnější. V praxi se obvykle přenáší sloupců více (hlavně z hlavní tabulky, což se projeví nejvíc), takže reálný výsledek bude něco mezi v článku prozkoumaným SELECT * a SELECT id, name. V tabulkách nejsou žádné bloby ani dlouhé texty, takže praxi se podle mě většinou bude spíš blížit výsledek SELECT *.
Prosazování jiného přístupu může být čistě pragmatické rozhodnutí. Komplexní dotaz je náročný na údržbu, konstantní počet dotazů je s tímto řešením výkonostně srovnatelný, takže někdy prostě může být levnější druhé řešení.
Megaloman:
Souhlasím, že v určitých specifických případech není komplexní dotaz správnou volbou, což jsem v předchozím příspěvku schválně zamlčel.Napadá mě například situace, kdy budu data z vedlejších tabulek cacheovat (mění se minimálně) a data z hlavní tabulky nebudu cacheovat (mění se neustále), pak dojde ke snížení počtu dotazů a přenesených dat.
Ale nemůžu souhlasit s tvrzením, že komplexní dotaz je náročný na sestavení a údržbu. Ano, první SQL dotaz je náročnější na složení a údržbu, ale co s tím související aplikační logika? Ta ve druhém případě není náročnější na sestavení a údržbu?
Vzít si do ruky datový model a promyslet spojení pár tabulek pomocí SUBSELECTů a/nebo OUTER/INNER/NATURAL JOINů by pro vývojáře neměl být problém. Pokud to problém je, není chyba v komplexnosti dotazu, ale v nekomplexnosti vývojářových znalostí SQL.
Navíc se první variantou dá do určité omezené míry "centralizovat" správa složitých dotazů pomocí VIEWS.
Druhá varianta je levnější pouze v případě, že programátor má mnohem lepší znalost PHP než SQL. A SQL je docela jednoduchý dotazovací jazyk...
Jakub Vrána :
Já s tebou v zásadě souhlasím, téměř výhradně používám komplexní dotazy, ale vadí mi tvůj dogmatizmus. Test ukazuje, že čistě z výkonnostního hlediska nemusí být jeden dotaz ideální. Z ekonomického hlediska to taky nemusí být ideální, protože než platit půl dne práce na komplexním dotazu, to raději zaplatím míň jednoduchých dotazů.
A co se aplikační logiky týče - ta je v tomto článku samozřejmě složitější u druhého řešení, ale je to jen proto, aby byl kód samonosný. Jak je v článku uvedeno, může se kód dramaticky zjednodušit přesunutím logiky do knihovny, takže druhé řešení se pak může psát obdobně jako třetí.
Megaloman:
Předchozí příspěvky ode mně vyzněli příliš tvrdě a nekompromisně, jako dogmatismus, ale chtěl jsem tím v podstatě jen říci, že:• DBMS jsou silně optimalizovány na tento typ úloh, proto by měly být využívány přednostně prostředky specializovaného nástroje před nástrojem obecným.
• Složit složitý SQL dotaz nemůže být pro DB specialistu problém, pokud se nespojují desítky tabulek.
• Komplexní dotaz se v určitých specifických případech nehodí.
S ekonomickou stránkou věci naprosto souhlasím, pokud je rychlejší (z hlediska lidské práce) varianta 2, pak by trvání na komplexním dotazu zavánělo neefektivní alokací zdrojů.
Ale "elegantní" mi přijde pouze první varianta, ostatně, kolik věcí se dá rychle splácat do funkčního stavu, ale Vývojáři to nedělají, protože jsou elegantnější způsoby?
Upřímně mě výsledky výkonnostních testů překvapily, ale aby bylo srovnání úplné, tak mi v té tabulce chybí řádek:
"Lokální server, bez SQL keše, jen vybrané sloupce"
Jakub Vrána :
Sestavit složitý dotaz je pro databázového specialistu samozřejmě není problém, ale sestavit ho tak, aby se vyhodnocoval efektivně (což je základní předpoklad pro to, abychom se vůbec zabývali náročností přenosů) je pracné a někdy až nemožné (nebo si vynutí vytvoření dopočítavaných sloupců se sadou aktualizačních triggerů, což může být z výkonnostního hlediska opět prospěšné, ale z ekonomického třeba zase už ne).
Naproti tomu sestavit jednoduchý dotaz je jednoduché i pokud se má vyhodnocovat efektivně.
Řádek jsem doplnil. Předpokládal jsem, že u něj bude obdobný poměr jako u prvního a druhého řádku, což se v zásadě potvrdilo, výsledek může být ale i tak zajímavý.
Megaloman:
Díky za doplnění...Jako u každé jiné lidské (ekonomické) činnosti je u více variant postupu nutné konfrontovat jejich náklady a výnosy a u složených dotazů je náročná hlavně jejich optimalizace, co jsem si zpočátku neuvědomil.
Ale přesto bych chtěl SQL nováčky varovat před bezhlavým nahrazováním funkcionality SŘBD aplikační logikou na straně klienta (v tomto případě PHP), protože až na výše uvedený případ se spojováním tabulek to povede k pomalejším a paměťově náročnějším aplikacím.
Tím nemyslím za každou cenu rvát do SQL aplikační logiku, ale naopak rozumně využívat všech možností databázového enginu, na kterém pracuji (NEpoužívat: SELECT * FROM ..., POužívat: triggery, pohledy, agregace, indexy, procedury...).
A kdo chce nebo musí, tak může za určitých okolností přesunout část aplikační logiky na DB server, ale to už je námět na jinou diskuzi/článek/knihu a jsem už IMHO OT.
Kajman:
Nemůže se u toho jednoho dotazu omezit tahání stejných dat díky použití jen potřebných mysql_result místo mysql_fetch_array? Jakub Vrána :
Ne. mysql_query() rovnou stáhne všechna data. I při použití mysql_unbuffered_query() by to ale bylo srovnatelně rychlé.
Juraj H.:
Díky za článok, výborné zrovnanie. Osobne mám za to, že záleží na objeme a počte dát, ktoré sa z DB ťahajú. Pri nejakých "stringoch" volím vždy prvý spôsob, príde mi prehľadnejší a najpohodlnejší, ale ak ťahám nejaké "blob" data, tak vždy separátne dotazy.Paja:
Dostal jsem se sem vicemene nahodou - ale tenhle test mi prijde nejaky podivny. Mozna sem to uplne nepochopil. Ale :SQL dotaz by mel vracet presne jen to co chci zobrazit. Pokud je treba data nasledne filtrovat je to problem spatne udelaneho SQL. Idealni je si napsat view. Nepsat slozite dotazy do PHP. Lip se to ladi. Kdyz pak neco zmenite v databazi tak staci predelat view. Jedno dobre napsane view navic vyuzijete ve vice dotazech v PHP.
Prenos dat vetsinou nehraje roli. Optimalizacni vyznam by to melo pokud by klic k vedlejsi tabulce (vetsinou 4 nebo 8 byte) byl vyrazne kratsi nez ziskana data z vedlejsi tabulky. Polozte si otazku. Kolik chcete zobrazit radku vysledku na jedne strance. 20? 100? 1000? 10000? Spis tech 20-50. Takze aby nastal nejaky meritelny vyznam objemu prenasenych dat, musel by mit kazdy udaj z vedlejsi tabulky minimalne stovky byte a maximalne se opakovat. Priklad: 50 radku, 5 ruznych 100 byte dlouhych textu: prenesete 50*4+5*100 byte = 700 byte misto 50x100 = 5000 byte. Ale co by jako mela prinest stranka kde se kazdy 100 byte dlouhy text 10x opakuje ? Uzivatel te stranky by z toho radost nemel. Pokud to bude 8 znaku (misto 100 - treba prumerny nazev mesta) tak je to 50*4+5*8= 240 byte vs. 400 byte. To uz ani nezmerite.
Zkuste misto mysql pouzivat postgres. Zacinal sem na mysql a command-line interface. Kdyz sem dostal do krve pgadmina, tak brecim kdyz musim delat neco s mysql. Optimalizace SQL : v pgadminu dostanete zmacknutim tlacitka prehledny obrazek query planneru.
Pokud nejaky SQL dotaz trva dlouho je to tim ze mate chybku. Bud je spatne napsany, nebo chybi indexy.
Jakub Vrána :
Zjevně jsi článek opravdu úplně nepochopil. Jde o to, že při jednom dotazu se musí řádky z hlavní tabulky přenést i u řádků z vedlejší tabulky – např. mě zajímají všechny informace o městech a k tomu jazyky, kterými se v nich mluví. Při jednom dotazu musím pro každý jazyk přenášet znovu a znovu informace o městech (když pominu MySQL specialitu GROUP_CONCAT, která zase prezentační logiku přenáší do SQL dotazu). Podívej se na obrázky na začátku článku, které dávají grafickou představu o tom, kolik dat se musí přenášet.
PostgreSQL si samozřejmě může každý také vyzkoušet (já jsem na něm začínal), s obsahem článku to ale nijak nesouvisí. Dovolím si odhadnout, že naměřené zákonitosti se projeví obdobně.
Poslední odstavec dokazuje, že jsi článek opravdu vůbec nepochopil. Článek není o efektivitě dotazů (všechny položené dotazy se vykonaly efektivně s použitím indexů), ale o efektivitě komunikace s databází.
mj41:
> U druhého přístupu jsou dotazy jednoduché, složitá je ale
> logika okolo
Ono záleží co a jak chceš pak s těmi daty dělat. V případě, že je budeš zobrazovat ne jako velkou tabulku, ale např:
* zeme1
** mesta
** jazyky
* zeme2
**
tak se to zamotává.
Navíc v případě, že chceme data nějak seřadit to taky bude zajímavější.
Já u složitých aplikací rozhodně preferuji kombinaci 1 a 2.
Leoš Ondra:
Zajímavá myšlenka, ale mám pár dotazů a poznámek:
1, jakým způsobem se vlastně přesně měřily ty časy?
2, dá se měřit skutečný objem přenášených dat? předpokládám, že mysql server a php klient komunikují binárně, ale do detailů nevidím
3, jedna věc je rychlost, druhá zátěž serveru (jak webserveru, kde je php, tak db serveru kde je mysql). Je to tak, že rychlejší dotaz(y) znamená automaticky menší zátěž procesoru a paměti?
4, "Medián se používá proto, že některé měření může ustřelit (typicky první, než se server probere a uvědomí si, že po něm něco chceme)."
Pokud je první dotaz i bez keše pokaždé (nebo typicky) pomalejší pak je jednak v měření něco shnilého, a jednak asi nerozumím tomu, jak db server dotazy zpracovává. Co to přesně znamená "uvědomí si, že po něm něco chceme"? Navíc, v řadě situací může zůstat jen u jednoho dotazu a pak ty další statistiku nevylepší prostě proto, že nejsou.
Jakub Vrána :
1. Čas jsem měřil funkcí microtime() v PHP. Jak je popsané v článku, tak test probíhal vždy jen z jednoho procesu.
2. Objem přenesených dat by se asi docela dobře dal měřit pomocí https://launchpad.net/mysql-proxy. Ale dobrou aproximaci poskytne i objem dat, které se dostanou do PHP.
3. To je složitější otázka. Ale většinou se dá říct, že rychle vyhodnocený dotaz zaneprázdní server míň.
4. Server si spoustu věcí ukládá do vyrovnávacích pamětí - ať už u disku, v operačním systému nebo přímo v databázovém systému. První načtení probíhá typicky z disku a je obvykle pomalejší než jakékoliv další načtení (říká se tomu warm up). Ideálně by měl test probíhat při emulaci reálného provozu, tam se ale výsledky špatně porovnávají.
Leoš Ondra:
Skleróza:
5, v jednom sql dotazu vyberu konzistentní data, ale u více dotazů musím řešit možnost, že se obsah tabulek mezi dotazy změní.
Jakub Vrána :
Pokud by mi to vadilo, tak můžu příkazy uzavřít do transakce a klást SELECT s modifikátorem LOCK IN SHARE MODE. Nebo rovnou nastavit SET TRANSACTION ISOLATION LEVEL na SERIALIZABLE.
Logik:
Čímž v konkurenčním prostředí kde někdo i zapisuje pošlu výkon totálně do kolen.... :-) Jakub Vrána :
No ano, přesnost něco stojí. Zápisy to samozřejmě zbrzdí.
peta:
Bohuzel se pridavam k tem protestujicim. Chyb tam bude vic, ale hnedka do oci bijici jsou ty echa, ktera bez ob_flush zatezuji nehorazne php. Pak tam nevidim pouziti transakci. Pokud spravne napises php kod a sql dotazy, tak by vsechny 3 vysledky meli byt priblizne stejne, ale v poradi, k jakemu jsi dospel, 1,2,3.
Jakub Vrána :
„echa“ jsou ve všech případech stejná, výsledky tedy nijak neovlivní. Vzhledem k tomu, že se nic nezapisuje, tak by použití transakcí výsledek téměř neovlivnilo. A proč výsledky rozhodně nebudou ani přibližně stejné, vysvětluje článek celkem podrobně.
peta:
Mozna to ne uplne chapes, co chci rici. Mas nekde original script, ktery vyhodi na zaver cas?Predpokladam, ze mas na zacatku microtime a na konci tez. Jenze, kdyz udelas echo a nemas to blokonane ob_flush, tak php posila vysledek hned uzivateli. Cimz blokne dalsi zpracovani scriptu. Pak pokracuje. 1000x echo muze vyvolat prave tech 15s navic. rozdil mezi local a vzdalenym serverem. A soucasne na localu to udela ty 3s. Proste by bylo fajn sem pridat odkaz na zip balicek se zdrojovymi kody a sql tabulkami. S tim, ze si odmazes hesla pro vzdaleny server :)
Jakub Vrána :
Benchmarky spouštím z příkazové řádky. „echo“ je navíc v kombinaci PHP s téměř jakýmkoliv webovým serverem díky bufferování výstupu téměř zadarmo (na rozdíl od prastarého ASP, kde sdružování výpisů bylo prakticky nevyhnutelné). Např. v Apachi by bylo potřeba nastavit http://httpd.apache.org/docs/current/en/mod/…#sendbuffersize na nízkou hodnotu, aby echo zdražilo. Navíc počet „echo“ je ve všech třech případech totožný.
Diskuse je zrušena z důvodu spamu.
Navigace
![]()
PHP triky
Kupte si mou knihu

Reklama
- Hledáte-li programátora nebo naopak sami programujete a nemáte do čeho píchnout, využijte služeb portálu nezávislých profesionálů Na volné noze.
Web běží na serveru
Články podle skupin
- Dobře míněné rady (112)
- Řešení problému (172)
- Výuka (100)
- Seznámení s oblastí (113)
- Ze zákulisí (69)
- Školení (31)
- Verze PHP (8)
- Osobní (46)
- Adminer (80)
Výběr článků
- Traverzování kolem stromu prakticky
- Vlastní pořadí řádků v tabulce
- Ukázka použití indexů
- Struktura stránek
- Unikátnost návštěvníka
- Vyhledávání v JavaScriptu
- Kontrola e-mailové adresy
- Vytvoření přátelského URL
- HTTP cachování
- Atomicita operací
- Vypnutí magic_quotes_gpc
- Ukládání souborů od uživatele
- Cross Site Scripting
- AJAX
- Přihlašování uživatelů
- MySQL 4.1 – kódování
- Vzájemné propojení souborů
- Diskuse s reakcemi
- Šablony
- HTTP metody GET a POST
- Escapování
- Ukládání hesel
- Využití unikátních klíčů v databázi
- Obrana proti SQL Injection