Storing multilingual records in the MySQL database
This article was published in the April 2009 issue of php|architect.
Multilingual applications use two types of texts requiring translation. The first ones are messages without a relation to the data (for example the title "Contents") which can easily be translated by GNU gettext or by a simple database table. The second type are texts related to the data (for example a German and Italian title for the same product with a given price). This article will examine database strategies for this second type of text.
Multilingual applications should use simple SQL queries (to avoid bugs), keep the performance high (which mainly means to utilize indexes) and produce the exact output (sort according to each language collation and respect the fulltext threshold). In additionally database consistency should be maintained, for example to preserve uniqueness of URLs. This article compares three different approaches for storing multilingual records considering these goals. In addition, the complexity of adding a new language and working with untranslated texts are covered.
This article demonstrates all approaches on a simple table of products with translatable names, URLs and descriptions, group identifiers and prices (common for all languages). The application needs to filter the products by the group identifier and then sort them by the name and we will perform a fulltext search on the name and description in a specified language. Therefore, in a single language environment, the table would look like this:

CREATE TABLE `product` ( `product_id` int(11) NOT NULL auto_increment, `group_id` int(11) NOT NULL, `name` varchar(50) NOT NULL, `url` varchar(50) NOT NULL, `price` decimal(9, 2) NOT NULL, `description` text NOT NULL, UNIQUE KEY `url` (`url`), KEY `group_id` (`group_id`, `name`), FULLTEXT KEY `name` (`name`, `description`), PRIMARY KEY (`product_id`) );
The unique index above URL guarantees that there can be only one product at each location. The query to retrieve the products in a given group sorted by the name is simple (PHP syntax is used):
" SELECT `url`, `name`, `price` FROM `product` WHERE `group_id` = $group_id ORDER BY `name` LIMIT 30 "
The usage of indexes is of course correct:
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | product | ref | group_id | group_id | 4 | const | 9 | Using where |
Translations in a separate table
We can store the translatable columns in a separate table:
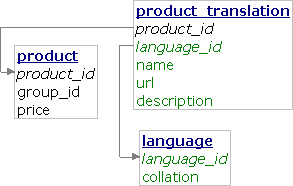
CREATE TABLE `language` ( `language_id` char(2) NOT NULL, `collation` varchar(64) NOT NULL, PRIMARY KEY (`language_id`) ); CREATE TABLE `product` ( `product_id` int(11) NOT NULL auto_increment, `group_id` int(11) NOT NULL, `price` decimal(9, 2) NOT NULL, KEY `group_id` (`group_id`), PRIMARY KEY (`product_id`) ); CREATE TABLE `product_translation` ( `product_id` int(11) NOT NULL, `language_id` char(2) NOT NULL, `name` varchar(50) NOT NULL, `url` varchar(50) NOT NULL, `description` tinytext NOT NULL, UNIQUE KEY `language_id_2` (`language_id`, `url`), KEY `language_id` (`language_id`, `name`), FULLTEXT KEY `name` (`name`, `description`), FOREIGN KEY (`language_id`) REFERENCES `language` (`language_id`), FOREIGN KEY (`product_id`) REFERENCES `product` (`product_id`), PRIMARY KEY (`product_id`, `language_id`) );
(The `language`.`collation` column contains one of the collations returned by the SHOW COLLATION command and we need it to properly sort the results.)
With this schema, a simple query to retrieve the products in a given group sorted by the name is not so simple:
" SELECT `product_translation`.`url`, `product_translation`.`name`, `product`.`price` FROM `product` INNER JOIN `product_translation` USING (`product_id`) WHERE `product`.`group_id` = $group_id AND `product_translation`.`language_id` = '$language_id' ORDER BY `product_translation`.`name` COLLATE $collation LIMIT 30 "
(Variable $collation is taken from `language`.`collation` in the application initialization.)
The query is complex and its execution plan is bad:
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | product | ref | PRIMARY, group_id | group_id | 4 | const | 12 | Using temporary; Using filesort |
| 1 | SIMPLE | product_translation | eq_ref | PRIMARY, language_id_2, language_id | PRIMARY | 10 | product.product_id, const | 1 | Using where |
Because of filesort, MySQL has to read all entries and cannot use the LIMIT clause to skip unnecessary rows. It is N * log N where as to perform the ordering with LIMIT clause would be a constant! MySQL cannost use the index on (language_id, name) for sorting at all because we need a different collation for every language.
What about fulltext search? MySQL natural language search ignores words occurring in at least half of the rows. Because all languages are mixed in one column, this feature will likely exclude most words and thus be useless. Fulltext search can be good in some scenarios but it has negative impact on performance. Moreover, MySQL cannot use a fulltext index together with a normal index so the fulltext must search in all languages and then restrict the results by hand.
In a real-world application, we have to deal with untranslated texts. Usually, we use some default language in the place of them. With this table schema, we have two options available to solve this problem:
- One option is to copy the default language version of all texts to the newly added language. This greatly complicates adding a new language to the application. It also complicates adding a new product. Unique index above URL would work but then we would have to insert all translations in a transaction and rollback the transaction in a case of conflict.
- The second option is to use the default language version if a translation does not exist. This makes Adding a language very simple (just inserting a row in the language table) but the so called "simple query" gets complicated even more
" SELECT IFNULL(`product_translation`.`url`, `product_default`.`url`) AS `url`, IFNULL(`product_translation`.`name`, `product_default`.`name`) AS `name`, `product`.`price` FROM `product` INNER JOIN `product_translation` `product_default` USING (`product_id`) LEFT JOIN `product_translation` ON `product`.`product_id` = `product_translation`.`product_id` AND `product_translation`.`language_id` = '$language_id' WHERE `product`.`group_id` = $group_id AND `product_default`.`language_id` = '$default_id' ORDER BY IFNULL(`product_translation`.`name`, `product_default`.`name`) COLLATE $collation LIMIT 30 "
Unique index above URL is useless as we would have to check for existence of the same URL in a trigger or a stored procedure at the time of inserting, updating and deleting a product translation.
Data copy
This approach copies also the data common to all languages.
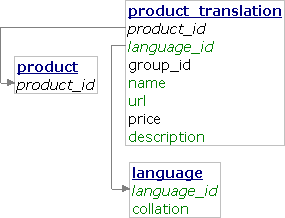
CREATE TABLE `language` ( `language_id` char(2) NOT NULL, `collation` varchar(64) NOT NULL, PRIMARY KEY (`language_id`) ); CREATE TABLE `product` ( `product_id` int(11) NOT NULL auto_increment, PRIMARY KEY (`product_id`) ); CREATE TABLE `product_translation` ( `product_id` int(11) NOT NULL, `language_id` char(2) NOT NULL, `group_id` int(11) NOT NULL, `name` varchar(50) NOT NULL, `url` varchar(50) NOT NULL, `price` decimal(9, 2) NOT NULL, `description` text NOT NULL, UNIQUE KEY `language_id_2` (`language_id`, `url`), KEY `language_id` (`language_id`, `group_id`, `name`), FULLTEXT KEY `name` (`name`, `description`), FOREIGN KEY (`product_id`) REFERENCES `product` (`product_id`), FOREIGN KEY (`language_id`) REFERENCES `language` (`language_id`), PRIMARY KEY (`product_id`, `language_id`) );
(The product table can be just a sequence.)
The group identifier and the price are copied to all languages. Technically a trigger can achieve it, however we have to define a trigger on all translatable tables in the database and it has to respect all columns in the table (so addition or modification of a table would be difficult). The data also takes more space so the working set is less likely to fit in memory.
The simple query remains simple:
" SELECT `url`, `name`, `price` FROM `product_translation` WHERE `language_id` = '$language_id' AND `group_id` = $group_id ORDER BY `name` COLLATE $collation LIMIT 30 "
Even the execution plan would be good only if it were not for the COLLATE clause:
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | product_translation | ref | language_id_2, language_id | language_id | 10 | const, const | 9 | Using where; Using filesort |
The COLLATE is causing a filesort which is bad for the LIMIT clause. The query would be fast without it but the results would not respect the sorting order specific for the language.
Both problems with fulltext search remain.
We have to solve the same dilemma as in the previous approach regarding untranslated texts and adding a new language. Either the queries will be complicated and slower or the language addition will be painful. Unique index would not work in the case of falling back to the default language or we would have to do all modifications in a transaction when copying the default language.
Translation directly in the data table
The previous approaches have one basic problem - they are storing different data (texts with miscellaneous collations) to the same column. We have to separate the languages into the individual columns to solve this basic problem:

CREATE TABLE `language` ( `language_id` char(2) NOT NULL, `collation` varchar(64) NOT NULL, PRIMARY KEY (`language_id`) ); CREATE TABLE `product` ( `product_id` int(11) NOT NULL auto_increment, `group_id` int(11) NOT NULL, `name_en` varchar(50) NOT NULL, `name_cs` varchar(50) collate utf8_czech_ci NOT NULL, `url_en` varchar(50) NOT NULL, `url_cs` varchar(50) collate utf8_czech_ci NOT NULL, `price` decimal(9, 2) NOT NULL, `description_en` text NOT NULL, `description_cs` text collate utf8_czech_ci NOT NULL, UNIQUE KEY `url_en` (`url_en`), UNIQUE KEY `url_cs` (`url_cs`), KEY `group_id_en` (`group_id`, `name_en`), KEY `group_id_cs` (`group_id`, `name_cs`), FULLTEXT KEY `name_cs` (`name_cs`, `description_cs`), FULLTEXT KEY `name_en` (`name_en`, `description_en`), PRIMARY KEY (`product_id`) );
(Notice the different collations for columns with translations.)
Each translatable field gets its own column in each language. The same holds for indexes - there are more of them but they are smaller.
The table is not nice but the simple query remains simple and produces correct results:
" SELECT `url_$language_id`, `name_$language_id`, `price` FROM `product` WHERE `group_id` = $group_id ORDER BY `name_$language_id` LIMIT 30 "
(The $language_id variable is whitelisted from `language`.`language_id`.)
It is also as fast as a single-language query:
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | product | ref | group_id_en, group_id_cs | group_id_en | 4 | const | 11 | Using where |
Both problems with fulltext search disappear. Each index has separate statistics and there is no need to filter by language identifier when performing the search.
Adding a language definitely will be a difficult operation so we do not need to solve the dilemma whether to store the default language to untranslated texts. It can be stored to keep query simplicity and speed. Unique indexes above URLs simply work.
Adding a new language will be a complex operation when this approach is used. We have to go through all tables and add a column for each language field. We also have to create new indexes. We can achieve it by a stored procedure or by a PHP function:
<?php /** Addition of language columns to all tables * @param string language identifier * @param string default language identifier * @param string way of ordering texts * @return null execution of commands ALTER TABLE and UPDATE * @copyright Jakub Vrana, https://php.vrana.cz/ */ function add_language($language_id, $default_id = "en", $collation = "") { $result = mysql_query("SHOW TABLES"); while ($row = mysql_fetch_row($result)) { // addition and copy of columns $alter = array(); $update = array(); $result1 = mysql_query("SHOW COLUMNS FROM $row[0]"); while ($row1 = mysql_fetch_assoc($result1)) { if (substr($row1["Field"], -3) == "_$default_id") { $field = substr($row1["Field"], 0, -2) . $language_id; $null = ($row1["Null"] == "NO" ? " NOT NULL" : ""); $alter[] = "ADD $field $row1[Type]" . ($collation ? " COLLATE $collation" : "") . "$null AFTER $row1[Field]"; $update[] = "$field = $row1[Field]"; } } mysql_free_result($result1); if ($alter) { mysql_query("ALTER TABLE $row[0] " . implode(", ", $alter)); mysql_query("UPDATE $row[0] SET " . implode(", ", $update)); // addition of indexes $indexes = array(); $result1 = mysql_query("SHOW INDEXES FROM $row[0]"); while ($row1 = mysql_fetch_assoc($result1)) { $type = ($row1["Index_type"] == "FULLTEXT" ? "FULLTEXT" : ($row1["Non_unique"] ? "INDEX" : "UNIQUE")); $indexes[$type][$row1["Key_name"]] .= "$row1[Column_name], "; } mysql_free_result($result1); foreach ($indexes as $type => $type_indexes) { foreach ($type_indexes as $index) { if (strpos($index, "_$default_id, ")) { mysql_query("ALTER TABLE $row[0] ADD $type (" . substr(str_replace("_$default_id, ", "_$language_id, ", $index), 0, -2) . ")"); } } } } } mysql_free_result($result); } ?>
The maximum row size in MySQL is about 64 KB so with big tables and many languages, this limit could be reached. In this case, it is possible to separate some columns to a different table with one-to-one relationship. Another approach would be to store each language in a separate table and copy common columns the same way as we did in the Data copy approach. This however involves problems with trigger maintenance.
Other databases
Other database systems such as Oracle or PostgreSQL do not have support for a collation definition in each column and use a different approach for a language-dependent sorting. They define (PostgreSQL through an extension) an nlssort function accepting a string to sort and a language identifier to sort by. The database systems can use this function together with partial function indexes to sort the products effectively in the Data copy schema. However, we still have to define the indexes at the time of adding a language.
Final thoughts
- For messages with no relation to the data (mentioned in the beginning of this article) we can use the same database schema to store translations. This way we can use the same infrastructure for translating both kinds of texts.
- Translators need a list of texts required for translation. We cannot generate this list by comparing messages that are the same as the default language because some translations are simply the same as original. We can maintain this list in a separate table.
- In the ideal world, all the translations would be stored in a single cell with complex data type. This data type would know how to sort the data in each language and how to use them in index. It would also know how to handle untranslated texts. However, we have to split the cell to either rows or columns in the world of relational databases.
Conclusion
Let's name pros and cons of all three approaches:
| Translations in a separate table | Data copy | Translation in the data table |
|---|---|---|
| - slow sorting - slow fulltext search - complex SQL queries Copy of default language: - complex language addition - complex product insertion - extra table for untranslated texts Fallback to default language: + simple language addition - even more complex SQL queries - complex URL modifications |
- slow or inaccurate sorting - slow fulltext search - bigger footprint - difficult table altering Copy of default language: + simple queries - complex language addition - complex product insertion - extra table for untranslated texts Fallback to default language: + simple language addition - complex SQL queries - complex any URL modification |
- variable database structure - very complex language addition Copy of default language: + simple queries + fast sorting + fast fulltext search - extra table for untranslated texts |
The third approach has a big handicap in the variable database structure (the user adding a language must have the ALTER privilege). It exceeds the other approaches in all other aspects and at the end of a day, we have to do the least work and still get a solution with the highest performance.
About the author
Jakub Vrána is one of the authors of official PHP manual, and he uses MySQL for developing web applications in PHP. He also teaches the MySQL basics at Charles University and conducts commercial trainings. He is the founder of compact MySQL management tool phpMinAdmin Adminer. Jakub lives in Prague, Czech Republic.
Comments
 Patrik Votoček (Vrtak-CZ):
Patrik Votoček (Vrtak-CZ):
Bude česká verze?
kluvi:
http://php.vrana.cz/ukladani-vicejazycnych-zaznamu.php
:-)nevim jestli je to uplne presne to stejny.. ale obsah je +/- stejnej :-)
 Jakub Vrána
Jakub Vrána  :
:
Ano, to je jednodušší článek na stejné téma. Kompletní překlad tohoto článku psát nebudu.
Marek Hrabě:
Prosím: http://translate.google.com/translate?prev=…&history_state0=Je to taková pseudo-čeština :D
Jinak koukni ta, kam psal kluvi...(#d-9028)
#d-9033 reply
Marek Hrabě:
Moc pěkný článek, Jakube! :) Jen by to možná chtělo zaměnit phpMinAdmin za Adminer...
Jakub Vrána :
Díky za upozornění. Ale jde o přetisk článku z php|architecta, takže v něm výjimečně změny dělat nebudu.
Mastodont:
Chybí mi tu čtvrtá možnost - samostatná tabulka pro každý jazyk překladu. Nevýhodou je sice proměnný počet tabulek, ale zase by se mělo značně vylepšit řazení. Jakub Vrána :
Ano, je to kompromis mezi druhým a třetím přístupem. Odstraňuje problémy
- slow or inaccurate sorting
- slow fulltext search
a naopak přidává
- variable database structure
- complex language addition (i ve variantě Fallback to default language)
Prdlořeznictví Krkovička, n. p.:
In additionally - buď Additionally, nebo In addition,MySQL cannost use the index - cannot nebo can not
+pár menších.
Dobrý článek. Díky, že ses o něj podělil.
Jakub Vrána :
Korektury si v php|architectu naštěstí dělali sami, článek byl celý červený :-). Sem jsem ale asi dal verzi bez korektur, protože se mi je nechtělo přenášet z jejich formátu do HTML.
Ludmila Pičmanová:
Ten limit 64 KB na řádku, ten platí pro součet všech sloupců kromě typů text a blob? Jakub Vrána :
Ano a je to skutečně bajtů (nikoliv znaků). Takže např. pro varchar(100) v kódování UTF-8 vyhradí MySQL 300 bajtů. Typy text a blob zabírají nějaké místo na pointery. InnoDB má navíc ještě vlastní limit, který je jen 8 KiB.
Hari KT:
Time for you to edit "He is the founder of compact MySQL management tool phpMinAdmin" and say adminer.
Thank you
Jakub Vrána :
Fixed, thanks.
Diskuse je zrušena z důvodu spamu.
Navigace
![]()
PHP triky
Kupte si mou knihu

Reklama
- Hledáte-li programátora nebo naopak sami programujete a nemáte do čeho píchnout, využijte služeb portálu nezávislých profesionálů Na volné noze.
Web běží na serveru
Články podle skupin
- Dobře míněné rady (112)
- Řešení problému (172)
- Výuka (100)
- Seznámení s oblastí (113)
- Ze zákulisí (69)
- Školení (31)
- Verze PHP (8)
- Osobní (46)
- Adminer (80)
Výběr článků
- Traverzování kolem stromu prakticky
- Vlastní pořadí řádků v tabulce
- Ukázka použití indexů
- Struktura stránek
- Unikátnost návštěvníka
- Vyhledávání v JavaScriptu
- Kontrola e-mailové adresy
- Vytvoření přátelského URL
- HTTP cachování
- Atomicita operací
- Vypnutí magic_quotes_gpc
- Ukládání souborů od uživatele
- Cross Site Scripting
- AJAX
- Přihlašování uživatelů
- MySQL 4.1 – kódování
- Vzájemné propojení souborů
- Diskuse s reakcemi
- Šablony
- HTTP metody GET a POST
- Escapování
- Ukládání hesel
- Využití unikátních klíčů v databázi
- Obrana proti SQL Injection