Struktura databáze pro čtečku odběrů
Když skončil Google Reader, tak jsem vyzkoušel několik dalších čteček a z jednoho nebo druhého důvodu jsem všechny shledal jako nepoužitelné. Většinou byly příšerně přetížené, takže prakticky nefungovaly. Uživatelské rozhraní, na které mám specifické požadavky především při čtení z mobilu, mi obvykle taky nevyhovovalo. Nakonec jsem rezignoval a za víkend si napsal čtečku vlastní fungující přesně podle mých potřeb (a především vůbec fungující). Nemám s ní žádné plány, nechci ji provozovat jako veřejnou službu a dopadnout jako ostatní přetížené čtečky… Ani kód nechci zveřejňovat, protože ho neplánuji podporovat, takže zveřejnění by vytvořilo abandonware. Nicméně některé zajímavé obraty popíšu.
Čtečku je vhodné rozdělit na dvě nezávislé části – jedna bude odběry stahovat a druhá je bude zobrazovat. Určitě nechceme, aby uživatel při načtení čtečky čekal, až se všechny odběry stáhnou. Stahovač bude ukládat strukturovaná data do databáze, zobrazovač je odtud bude číst. I když čtečku plánuji používat sám, tak jsem ji udělal jako víceuživatelskou, co kdyby náhodou. Odběry všech uživatelů se budou ukládat do stejné tabulky a mezi uživateli a odběry bude vztah M:N. Pokud by více uživatelů mělo přihlášený stejný odběr, tak ho díky této struktuře stačí stáhnout jen jednou.
Ve stahovači dále rozdělíme samotné stahování a parsování XML na jednotlivé příspěvky. Kompletní XML si budeme ukládat pro případ, že bychom v parseru časem objevili chybu nebo ho chtěli vylepšit. V tom případě nebudeme muset všechny odběry stahovat znovu a bude stačit již jednou stažené odběru znovu prohnat parserem. Originál XML uložíme jako mediumblob, protože dokud XML nezpracujeme, tak si nemůžeme být jisti jeho kódováním. To se totiž dá určit buď v HTTP hlavičce Content-Type nebo v XML deklaraci <?xml encoding ?>.
Příspěvky ze zpracovaného odběru uložíme přímo jako HTML. Některé odběry totiž mohou obsahovat formátovaný text a bylo by škoda o toto formátování přijít. Jen musíme HTML prohnat nějakým nástrojem, který v něm nechá pouze bezpečné obraty. Lze použít HTML Purifier, což je sice moloch, který má i v single-file verzi 143 souborů, ale nic lepšího bohužel neznám.
Zásadní otázka, kterou musíme vyřešit, je vybrat, jak budeme označovat přečtené příspěvky. Máme v zásadě dvě možnosti:
- Ukládat přečtené příspěvky. Tabulka přečtených příspěvků bude nekontrolovaně růst spolu s tím, jak budou uživatelé aplikaci používat. Všechny dotazy na nepřečtené příspěvky navíc budou muset s touto obří tabulkou pracovat.
- Ukládat nepřečtené příspěvky. Při objevení nového příspěvku ho vložíme všem uživatelům a když si ho přečtou, tak vazbu zase smažeme. Pro aktivní uživatele tabulka zůstane rozumně malá. Pro neaktivní uživatele ale tabulka bude neustále bobtnat.
Ani jedno řešení nevypadá moc slibně. Můžeme proto sáhnout po trochu netradičním řešení – budeme si ukládat pouze ID naposledy přečteného příspěvku v každém odběru. V dotazu na nové příspěvky pak použijeme operátor >. To klade jistá omezení na uživatelské rozhraní – příspěvky je potřeba zobrazovat od nejstaršího a přečtení jednoho označí jako přečtené i všechny předchozí. To mi ovšem zcela vyhovuje. Někdy uživatel může chtít příspěvek nechat jako nepřečtený, k tomu zavedeme vazbu mezi uživateli a příspěvky, kam si tuto informaci poznamenáme. Tu bychom ostatně mohli využít i pro čtení příspěvků v jiném než chronologickém pořadí.
A to je v podstatě vše.
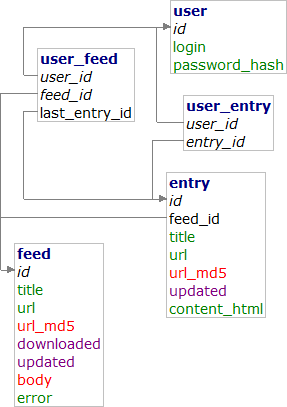
Schéma databáze znázorňuje datové typy (barvami), primární klíče (kurzívou) a vazby mezi tabulkami. Nad sloupci login a url_md5 jsou unikátní klíče, nad sloupci feed_id, last_entry_id je složený index (který by ostatně mohl být i cizím klíčem do tabulky entry). Nad sloupcem feed.updated je index, který se používá při výběru odběrů, které budeme stahovat častěji než ostatní.
Diskuse
Martin:
V čem je špatná třeba Feedly? Vždyť má i komfortního mobilního klienta. Jakub Vrána
Jakub Vrána  :
:
Feedly mi dva dny hlásila, že je přetížená.
Staňa:
Feedly to skutečně hlásilo, u mě se to ale vyřešilo aktualizací klienta.Psaní vlastní čtečky chápu, také se k něčemu podobnému odhodlávám; rád bych totiž zdroje třídil do skupin podle typu média a dalšího nakládání (stahovat nadpis/perex/text, vyžadovat přečtení, prioritní zdroje...) což jsem zatím u žádné čtečky nenašel.
v6ak:
Tak některé věci umí TT-RSS, někdy s pomocí pluginu. Případně je možné si napsat vlastní plugin. Nevím teda, jak moc dobře chápu Tvoje požadavky, píšeš je stručně, ale:
* Vytáhnout text ze článku umí např. feedmod: https://github.com/mbirth/ttrss_plugin-af_feedmod
* Pomocí filtrů je možné některé články rovnou označit za přečtené, dát jim jinou prioritu (zobrazí se dole/nahoře) apod. (To možná budou ty prioritní zdroje.)
* Ke každému feedu je možné si nechat nastavit čištění - staré články se automaticky smažou po nastavené době (třeba nikdy). (To by mohlo být to "vyžadovat přečtení".)
* Co nenajdeš, můžeš si napsat jako plugin. Nemusíš psát celou čtečku.
Jakub Vrána :
Mé požadavky jsou velmi skromné:
Chci, abych se o nových příspěvcích dozvěděl co nejdřív. Mám některé zdroje, které se často aktualizují, ty chci vidět co nejdřív po aktualizaci.
Rozhraní pro čtení mi v zásadě vyhovovalo u Google Readeru, s jedinou výjimkou toho, že příspěvky označené jako nepřečtené se odoznačily po přečtení nějakého pod ním.
Celá moje čtečka má 345 řádek zdrojáku, bavilo mě ji vyrábět, chová se přesně tak, jak potřebuji, můžu si ji jakkoliv upravit. Když bych hledal něco hotového, co si případně můžu dobastlit, tak tím nejspíš strávím víc času, nebude mě to bavit a výsledek nejspíš nebude přesně odpovídat tomu, co chci. Nevidím jediný důvod, proč bych to dělal.
v6ak:
Tomu rozumím. Já reagoval na Staňu. Pokud se k psaní vlastní čtečky teprve odhodlává a je trochu náročnější, pak použití existujícího SW může dávat smysl.
Wegguy:
Obávám se, že pokud bude čtečka ukládat všechny příspěvky, na které kdy narazila, tak bude databáze růst nekontrolovaně tak jako tak a jeden příznak přečteno/nepřečteno pro každý příspěvek a uživatyele už to o moc nezhorší. Takže ta otázka mi nepřijde tak zásadní.Jinak pokud některý ze čtenářů také plánuje napsat si vlastní čtečku, doporučuji nejdřív kouknout na Tin Tiny RSS - http://tt-rss.org/ - není to služba, je to implementace v PHP k nasazení na vlastním serveru.
 Lukenzi:
Lukenzi:
Přesně tak, ukládat vše do databáze je docela smrtící volba (jediná výhoda je v tom, že můžeme vyhledávat ve starších článcích, ale třeba já toto nikdy nepoužil). Daleko užitečnější mi příjde využít SimplePie, která umožňuje ukládat feedy třeba do souborové cache. Není tak problém načítat zdroje pravidelně například cronem, nebo ajaxem při stránkování. Odpadne mi tímto práce s db a s 90% obsahu tohoto článku, aneb proč vynalézat kolo (také mám podobnou čtečku na lokále - funguje naprosto dokonale).
Jakub Vrána :
Neexistuje jediný důvod, proč místo databáze v tomto případě zvolit soubory na disku.
Jakub Podhorský:
Proč by to měla být proboha smrtící volba? Databáze jak už název napovídá je pro ukládání dat uzpůsobená.Jak si myslíte, že mají uloženy informace o produktech navštěvované eshopy nebo zpravodajské portály, kde ty objemy dat budou řádově vyšší? V souborové cache to určitě nebude.
v6ak:
Google Reader patrně řešil přečtené/nepřečtené tak, že si ukládal seznam nepřečtených (to mi ostatně přijde praktičtější na manipulaci, lépe se nad tím bude dotazovat) a položky starší než cca 30d označovat za přečtené. (Tedy při ukládání seznamu nepřečtených mazal.)
Podobně to AFAIK dělá i TT-RSS, ale dá se to vypnout. Nevím nicméně, zda je to možné nějak zakázat, což by se hodilo na nějakém veřejném "hostingu".
Jinak se zeptám, co vadí na TT-RSS? Je to velmi podobně Google Readeru, snad až na možnost mít feed ve více kategoriích současně. Umí to filtry, takže si některé zprávy (např. ReTweety, některé autory a některá klíčová slova) prioritizuju a některé trošku "schovávám" (např. odpovědi na tweety, možná je budu úplně mazat). Plus tu jsou různé pluginy. Ano, mohl bych si něco podobného napsat sám, ale proč bych to dělal. A mobilní aplikaci se mi k tomu taky psát nechce, zatímco k TT-RSS existuje několik (snad brzy dospěje News+).
Jakub Vrána :
Na TT-RSS mi nevadilo nic, ani jsem to nezkoušel.
Já nesnáším hledání hotových věcí. S čtečkou jsem to podstoupil, řekl jsem si: „No tak přece si nebudu psát vlastní čtečku, že ne.“ Asi půl dne jsem strávil hledáním a zkoušením čteček, bylo to pro mě utrpení a nakonec jsem odešel s prázdnou. Tak místo dalšího otravného půl dne hledání s nejistým výsledkem jsem radši strávil den něčím, co mě baví a o čem vím, že to bude fungovat přesně tak, jak si představuji, a to i do budoucna.
„Ano, mohl bych si něco podobného napsat sám, ale proč bych to dělal.“
Protože mě to baví a protože výsledek bez kompromisů je zaručen.
Mobilní aplikaci jsem nepsal, mně bohatě stačí webová stránka s trochou responzivity.
 Michal:
Michal:
Dobry den Jakube, nas donutil masivni zajem o nasi ctecku G2Readek k vyraznemu posileni hardware a uz cca 3-4 tydne nebyva pretizena coz je ale take tim, ze se po datu vypnuti sluzby stabilizoval zajem o sluzbu. Mesic pred ukoncenim sluzby GR se registrovali i tisice lidi denne, ted jsou to jen stovky.
Kazdopadne chci podekovak vsem nasim uzivatelum za trpelivost v onom hektickem obdobi a do bodoucna oplatime sluzbami nad ramec ctecky popsane v tomto clanku. Tak napriklad uz dnes mezete sledovat "Trending" prispevky oktualizovane kazdych nekolik minut. Realne sestavene nad zajmem uzivatelu z jednotlivich zemi.
Hezky den
 Ondřej Mirtes:
Ondřej Mirtes:
Já jsem se po vyzkoušení Feedly a Flowreaderu usadil u placeného Feedbinu - $3 měsíčně, použitelné webové UI, podpora v nativním Reederu pro iPhone, řešení problémů a přijmání návrhů na zlepšení pomocí issues na GitHubu.
ajax:
Skoda, ze to nechces dat ven, skoda....Koubas:
Chápu, že přesné záznamy o přečtených/nepřečtených článcích nepotřebuješ, ale stejně mi nedalo se nezamyslet nad tím, jak to dělat co nejefektivněji.Co ukládat rozsahy přečtených (nebo nepřečtených) bloků článků? Za předpokladu, že články jsou řazeny dle ID, by záznam v tabulce přečtených obsahoval ID prvního a posledního článku v bloku, který je přečtený.
Když si vezmu, že většina uživatelů má buď hodně po sobě jdoucích bloků přečtených, či nepřečtených článků a hodně lidí si např. před zavřením čtečky označuje vše jako přečtené, by tato v-podstatě-komprese byla IMHO dosti účinná.
Je k tomu potřeba jen o trochu sofistikovanější logika na straně čtečky, která např při přečtení článku rozdělí blok, ve kterém byl, na dva, a pod.
Franta:
IMHO se tu vymýšlejí různá zbytečně složitá řešení a předčasné optimalizace. V databázi bych jednoduše ukládal nepřečtené položky a jejich rozlišení a aktualizaci stavu bych měl na jednom místě – buď v datové vrstvě aplikace nebo v databázi (pohled, procedura). Pokud by byl problém s výkonem, stačí optimalizovat tuhle jednu vrstvu. Případně je tu možnost staré příspěvky označovat jako přečtené – některé služby zruší uživatelům účet po půlroční neaktivitě, tady by se nemusel rušit účet, ale po určité době by úloha z cronu označila (DELETE) všechny starší příspěvky za přečtené.
P.S. řešil jste někdo tuhle úlohu v reálné praxi a dostali jste se za hranici toho, kdy toto jednoduché řešení na běžném HW už nefunguje? Jaké řešení jste pak zvolili?
Michal:
V DB na G2Reader.com používáme pro označení nepřečtených jeden záznam v tabuli pro každou položku a uživatele. Vše přečtené = žádné záznamy. Každou minutu registrujeme několik tisíc nových položek ve feedech a dá se to zpracovat celkem bez problémů.
Omezujeme pouze max počet položek na feed kvůli příliš upovídaným feedům.
Navrhované řešení Jakuba se mi zdá vhledem k plánovanému způsobu nasazení zbytečně omezující.
Diskuse je zrušena z důvodu spamu.
Navigace
![]()
PHP triky
Kupte si mou knihu

Reklama
- Hledáte-li programátora nebo naopak sami programujete a nemáte do čeho píchnout, využijte služeb portálu nezávislých profesionálů Na volné noze.
Web běží na serveru
Články podle skupin
- Dobře míněné rady (113)
- Řešení problému (172)
- Výuka (100)
- Seznámení s oblastí (113)
- Ze zákulisí (69)
- Školení (31)
- Verze PHP (8)
- Osobní (46)
- Adminer (81)
Výběr článků
- Traverzování kolem stromu prakticky
- Vlastní pořadí řádků v tabulce
- Ukázka použití indexů
- Struktura stránek
- Unikátnost návštěvníka
- Vyhledávání v JavaScriptu
- Kontrola e-mailové adresy
- Vytvoření přátelského URL
- HTTP cachování
- Atomicita operací
- Vypnutí magic_quotes_gpc
- Ukládání souborů od uživatele
- Cross Site Scripting
- AJAX
- Přihlašování uživatelů
- MySQL 4.1 – kódování
- Vzájemné propojení souborů
- Diskuse s reakcemi
- Šablony
- HTTP metody GET a POST
- Escapování
- Ukládání hesel
- Využití unikátních klíčů v databázi
- Obrana proti SQL Injection